

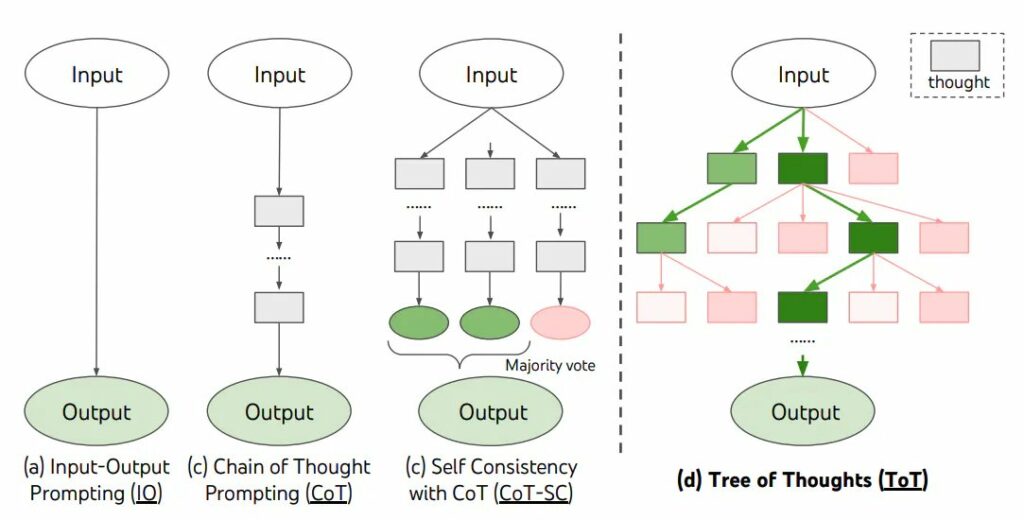
Đối với các nhiệm vụ phức tạp đòi hỏi nhiều suy luận diễn tiến, các kỹ thuật nhắc nhở truyền thống hoặc đơn giản sẽ không hiệu quả. Yao và cộng sự. (2023) và Long (2023) đã đề xuất một phương pháp đó Cây suy nghĩ (ToT), một framework khái quát hóa việc thúc đẩy chuỗi suy nghĩ tiếp diễn (Tree of Thoughts) và khuyến khích khám phá những suy nghĩ đóng vai trò là bước trung gian để giải quyết vấn đề chung bằng mô hình ngôn ngữ.
ToT duy trì một cây suy nghĩ, trong đó các suy nghĩ thể hiện một chuỗi ngôn ngữ mạch lạc đóng vai trò là bước trung gian để giải quyết vấn đề. Cách tiếp cận này cho phép mô hình ngôn ngữ LM tự đánh giá tiến trình thông qua những suy nghĩ trung gian được thực hiện để giải quyết vấn đề thông qua quá trình suy luận có chủ ý. Sau đó, khả năng tạo và đánh giá suy nghĩ của LM được kết hợp với các thuật toán tìm kiếm (ví dụ: tìm kiếm theo chiều rộng và tìm kiếm theo chiều sâu) để cho phép khám phá các suy nghĩ một cách có hệ thống bằng cách xem trước và quay lại.
Framework ToT được minh họa dưới đây:
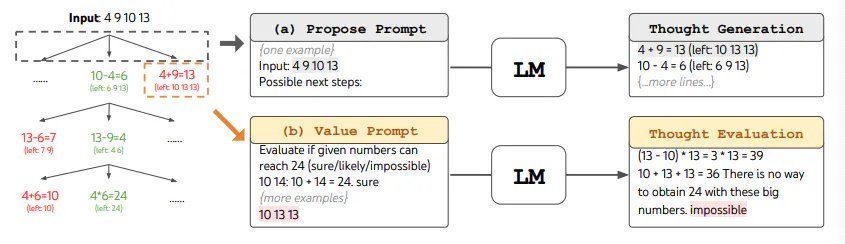
Khi sử dụng ToT, các nhiệm vụ khác nhau yêu cầu xác định số lượng tác nhân và số lượng suy nghĩ/bước. Ví dụ, như đã trình bày trong bài báo, Game 24 được sử dụng như một bài tập suy luận toán học, đòi hỏi phải chia các suy nghĩ thành 3 bước, mỗi bước liên quan đến một phương trình trung gian. Ở mỗi bước, b=5 ứng cử viên tốt nhất được giữ lại.
Để thực hiện BFS trong ToT cho nhiệm vụ Game 24, LM được nhắc đánh giá từng ứng cử viên được cho là “chắc chắn/có thể/không thể” liên quan đến việc đạt được Game 24. Như các tác giả đã nêu, “mục đích là thúc đẩy các giải pháp từng phần chính xác điều đó có thể được đưa ra phán quyết trong một số thử nghiệm xem trước và loại bỏ các giải pháp từng phần không thể thực hiện được dựa trên lẽ thường “quá lớn/nhỏ” và giữ phần còn lại là “có thể””. Các giá trị được lấy mẫu 3 lần cho mỗi suy nghĩ. Quá trình này được minh họa dưới đây:
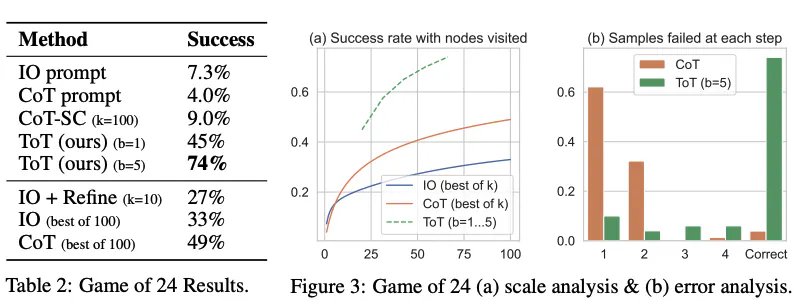
Từ kết quả được báo cáo trong hình bên dưới, ToT vượt trội hơn đáng kể so với các phương pháp nhắc khác:
Ở mức độ cao, những ý tưởng chính của Yao et el. (2023) và Long (2023) giống nhau. Cả hai đều nâng cao khả năng của LLM trong việc giải quyết vấn đề phức tạp thông qua tìm kiếm cây thông qua cuộc trò chuyện nhiều vòng. Một trong những khác biệt chính là Yao thúc đẩy tìm kiếm DFS/BFS/Bean, trong khi chiến lược tìm kiếm dạng cây (tức là khi nào nên quay lui và quay lại theo bao nhiêu cấp độ, v.v.) được đề xuất trong nghiên cứu của Long (2023) được điều khiển bởi “Bộ điều khiển ToT” được đào tạo thông qua học tập tăng cường. Tìm kiếm DFS/BFS/Beam là các chiến lược tìm kiếm giải pháp chung chung không thích ứng với các vấn đề cụ thể.
Để so sánh, Bộ điều khiển ToT được đào tạo thông qua RL có thể học từ tập dữ liệu mới hoặc thông qua tính năng tự phát (tìm kiếm AlphaGo so với tìm kiếm brute force) và do đó, hệ thống ToT dựa trên RL có thể tiếp tục phát triển và học hỏi kiến thức mới ngay cả khi đã sửa lỗi LLM.
Hulbert (2023) đã đề xuất giải pháp Nhắc nhở theo cây suy nghĩ, áp dụng khái niệm chính từ khung ToT như một kỹ thuật nhắc nhở đơn giản, giúp LLM đánh giá các suy nghĩ trung gian chỉ trong một lời nhắc duy nhất. Lời nhắc ToT mẫu là:
Imagine three different experts are answering this question.
All experts will write down 1 step of their thinking,
then share it with the group.
Then all experts will go on to the next step, etc.
If any expert realises they're wrong at any point then they leave.
The question is...Mặt trời (2023) đã đánh giá Nhắc nhở cây tư duy bằng các thử nghiệm quy mô lớn và giới thiệu PanelGPT — một ý tưởng nhắc nhở bằng các cuộc thảo luận của Panel giữa các LLM.