

Có một điều thật không may mắn đối với một Kỹ sư học máy đó là việc thiếu hoặc có rất ít dữ liệu được gắn nhãn. Thông thường, khi nhận ra điều này, các dự án sẽ bắt tay vào một quá trình lâu dài để thu thập và ghi nhãn dữ liệu. Chỉ sau một vài tháng người ta mới có thể bắt đầu phát triển một giải pháp.
Tuy nhiên, với sự ra đời của LLM, mô hình đã thay đổi ở một số sản phẩm: Giờ đây người ta có thể dựa vào khả năng khái quát hóa của LLM và thử nghiệm ý tưởng hoặc phát triển tính năng hỗ trợ AI gần như ngay lập tức. Nếu nó hoạt động (gần như) như dự định thì quá trình phát triển truyền thống có thể bắt đầu.

Một trong những cách tiếp cận mới nổi là Tạo sinh dựa trên truy xuất tăng cường (RAG). Nó được sử dụng cho các nhiệm vụ đòi hỏi nhiều kiến thức mà bạn không thể chỉ dựa vào kiến thức của mô hình. RAG kết hợp thành phần truy xuất thông tin với mô hình tạo văn bản.
Thành phần chính của RAG là mô hình Truy xuất xác định các tài liệu liên quan và chuyển chúng đến LLM để xử lý thêm. Hiệu suất của mô hình Truy xuất càng tốt thì kết quả sản phẩm hoặc tính năng càng tốt. Lý tưởng nhất là Truy xuất hoạt động tốt ngay lập tức. Tuy nhiên, hiệu suất của nó thường giảm ở các ngôn ngữ khác nhau hoặc ở một số lĩnh vực cụ thể.
Hãy tưởng tượng điều này: bạn cần tạo một chatbot trả lời các câu hỏi dựa trên luật pháp và thông lệ pháp lý của Việt (tất nhiên là bằng tiếng Việt). Hoặc thiết kế trợ lý thuế (một trường hợp sử dụng đã được OpenAI giới thiệu trong buổi thuyết trình GPT-4) cho thị trường Ấn Độ. Bạn có thể sẽ thấy rằng mô hình Truy xuất thường bỏ lỡ các tài liệu có liên quan nhất và không hoạt động tốt về tổng thể do đó dẫn đến các hạn chế chất lượng của hệ thống.
Nhưng có một giải pháp. Một xu hướng mới nổi liên quan đến việc sử dụng LLM hiện có để tổng hợp dữ liệu cho việc đào tạo các thế hệ LLM/Retriever/mô hình khác mới. Quá trình này có thể được xem như là quá trình chắt lọc xử lý dữ liệu LLM thành các bộ dữ liệu có kích thước tiêu chuẩn thông qua việc tạo truy vấn dựa trên lời nhắc. Mặc dù quá trình xử lý này đòi hỏi nhiều tính toán nhưng nó làm giảm đáng kể chi phí suy luận và có thể nâng cao hiệu suất đáng kể của mô hình, đặc biệt là trong các ngôn ngữ có nguồn dữ liệu được đào tạo thấp cho mô hình ngôn ngữ gốc hoặc các lĩnh vực chuyên biệt.
Trong hướng dẫn này, chúng tôi sẽ dựa vào các mô hình tạo văn bản mới nhất, như ChatGPT và GPT-4, những mô hình này có thể tạo ra lượng lớn nội dung tổng hợp theo hướng dẫn. Đại và cộng sự. (2022) đã đề xuất một phương pháp trong đó chỉ với 8 ví dụ được gắn nhãn thủ công và một lượng lớn dữ liệu chưa được gắn nhãn (tài liệu để truy xuất, ví dụ: tất cả các luật được phân tích cú pháp), người ta có thể đạt được hiệu suất gần như Hiện đại. Nghiên cứu này xác nhận rằng dữ liệu được tạo tổng hợp tạo điều kiện thuận lợi cho việc đào tạo các trình truy xuất theo nhiệm vụ cụ thể cho các nhiệm vụ trong đó việc tinh chỉnh trong miền được giám sát là một thách thức do khan hiếm dữ liệu.
Tạo tập dữ liệu theo lĩnh vực cụ thể
Để sử dụng LLM, người ta cần cung cấp mô tả ngắn gọn và gắn nhãn thủ công cho một số ví dụ. Điều quan trọng cần lưu ý là các tác vụ truy xuất khác nhau có mục đích tìm kiếm khác nhau, nghĩa là các định nghĩa khác nhau về “mức độ liên quan”. Nói cách khác, đối với cùng một cặp (Truy vấn, Tài liệu), mức độ liên quan của chúng có thể hoàn toàn khác nhau dựa trên mục đích tìm kiếm. Ví dụ: một tác vụ truy xuất đối số có thể tìm kiếm các đối số hỗ trợ, trong khi các tác vụ khác yêu cầu các đối số phản đối (như đã thấy trong tập dữ liệu ArguAna).
Hãy xem xét ví dụ dưới đây. Mặc dù được viết bằng tiếng Anh để dễ hiểu hơn nhưng hãy nhớ rằng dữ liệu có thể ở bất kỳ ngôn ngữ nào vì ChatGPT/GPT-4 xử lý hiệu quả ngay cả những ngôn ngữ có nguồn tài nguyên thấp.
Lời nhắc:
Task: Identify a counter-argument for the given argument.
Argument #1: {insert passage X1 here}
A concise counter-argument query related to the argument #1: {insert manually prepared query Y1 here}
Argument #2: {insert passage X2 here}
A concise counter-argument query related to the argument #2: {insert manually prepared query Y2 here}
<- paste your examples here ->
Argument N: Even if a fine is made proportional to income, you will not get the equality of impact you desire. This is because the impact is not proportional simply to income, but must take into account a number of other factors. For example, someone supporting a family will face a greater impact than someone who is not, because they have a smaller disposable income. Further, a fine based on income ignores overall wealth (i.e. how much money someone actually has: someone might have a lot of assets but not have a high income). The proposition does not cater for these inequalities, which may well have a much greater skewing effect, and therefore the argument is being applied inconsistently.
A concise counter-argument query related to the argument #N:Đầu ra:
punishment house would make fines relative incomeNói chung, lời nhắc như vậy có thể được thể hiện như sau:
\((e_{\text{prompt}},e_{\text{doc}}(d_1)), e_{\text{query}}(q_1),…,e_{\text{doc}}(d_k),e_{\text{query}}(d_k),e_{\text{doc}}(d))\), ở đây \(e_{\text{doc}}\) và \(e_{\text{query}}\) lần lượt là tài liệu dành riêng cho nhiệm vụ, mô tả truy vấn, \(e_{\text{prompt}}\) là lời nhắc/hướng dẫn dành riêng cho nhiệm vụ dành cho ChatGPT/GPT-4 và𝑑 là một tài liệu mới mà LLM sẽ tạo một truy vấn.
Từ lời nhắc này, chỉ có tài liệu cuối cùng 𝑑 và truy vấn được tạo sẽ được sử dụng để đào tạo thêm mô hình cục bộ. Cách tiếp cận này có thể được áp dụng khi một kho dữ liệu truy xuất mục tiêu 𝐷 có sẵn nhưng số lượng cặp tài liệu truy vấn được chú thích cho tác vụ mới bị hạn chế.
Tổng quan về toàn bộ tiến trình:
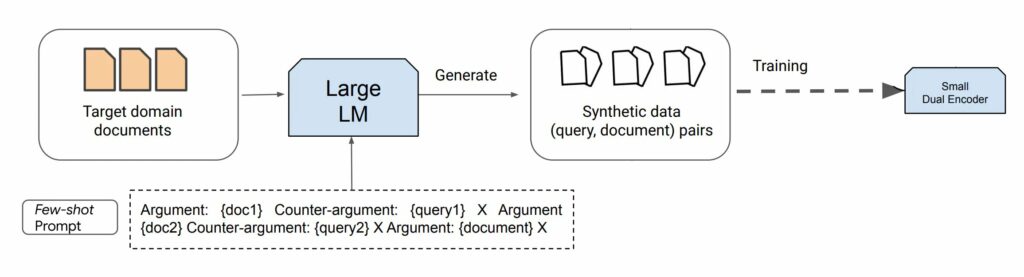
Điều quan trọng là phải xử lý chú thích thủ công các ví dụ một cách có trách nhiệm. Tốt hơn là bạn nên chuẩn bị nhiều hơn (ví dụ: 20) và chọn ngẫu nhiên 2-8 trong số chúng theo lời nhắc. Điều này làm tăng tính đa dạng của dữ liệu được tạo ra mà không tốn nhiều thời gian cho việc chú thích. Tuy nhiên, những ví dụ này phải mang tính đại diện, được định dạng chính xác và thậm chí cả những chi tiết cụ thể như độ dài truy vấn mục tiêu hoặc giọng điệu của nó. Các ví dụ và hướng dẫn càng chính xác thì dữ liệu tổng hợp sẽ càng tốt cho việc huấn luyện Retriever. Các ví dụ về few-shot chất lượng thấp có thể tác động tiêu cực đến chất lượng kết quả của mô hình được đào tạo.
Trong hầu hết các trường hợp, sử dụng mô hình giá cả phải chăng hơn như ChatGPT là đủ vì nó hoạt động tốt với các lĩnh vực và ngôn ngữ khác ngoài tiếng Anh. Giả sử, một lời nhắc có hướng dẫn và 4-5 ví dụ thường chiếm 700 token (giả sử mỗi đoạn không dài hơn 128 token do hạn chế của Retriever) và số lượng tạo ra là 25 token. Do đó, việc tạo một tập dữ liệu tổng hợp cho một kho tài liệu gồm 50.000 tài liệu để tinh chỉnh mô hình cục bộ sẽ có chi phí: 50,000 * (700 * 0.001 * $0.0015 + 25 * 0.001 * $0.002) = 55, ở đây $0.0015 và $0.002 là chi phí cho mỗi 1.000 token trong API GPT-3.5 Turbo. Thậm chí có thể tạo 2-4 ví dụ truy vấn cho cùng một tài liệu. Tuy nhiên, lợi ích của việc đào tạo thêm thường rất đáng giá, đặc biệt nếu bạn sử dụng Retriever không phải có cùng lĩnh vực chung (như truy xuất tin tức bằng tiếng Anh) mà cho một miền cụ thể (như luật Việt Nam, như đã đề cập).
Con số 50.000 không phải là ngẫu nhiên. Trong nghiên cứu của Đại et al. (2022), người ta tuyên bố rằng đây là số lượng dữ liệu được gắn nhãn thủ công cần thiết cho một mô hình để phù hợp với chất lượng của dữ liệu được đào tạo về dữ liệu tổng hợp. Hãy tưởng tượng bạn phải thu thập ít nhất 10.000 mẫu trước khi tung ra sản phẩm của mình! Sẽ mất không dưới một tháng và chi phí lao động chắc chắn sẽ vượt quá một nghìn đô la, nhiều hơn so với việc tạo ra dữ liệu tổng hợp và đào tạo Mô hình Retriever địa phương. Giờ đây, với kỹ thuật bạn học hôm nay, bạn có thể đạt được mức tăng trưởng số liệu hai con số chỉ trong vài ngày!
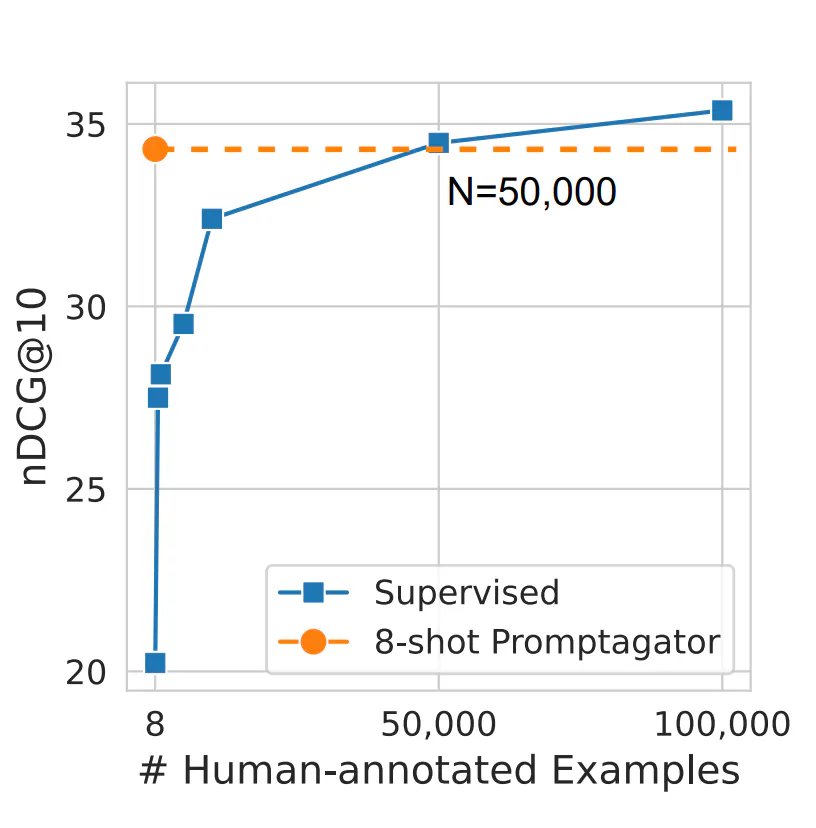
Và đây là các mẫu nhắc nhở từ cùng một bài báo cho một số bộ dữ liệu trong điểm chuẩn BeIR.
