

Trong bài trước, chúng ta đã thảo luận về tiềm năng của việc sử dụng LLM để tạo tập dữ liệu tổng hợp nhằm hoàn thiện hơn nữa mô hình cục bộ tăng cường. Phương pháp đó cần thực hiện được do lượng lớn tài liệu mà chúng ta đang có chưa được gắn nhãn. Mỗi tài liệu được sử dụng để tạo một hoặc nhiều truy vấn tổng hợp và tạo thành một cặp tài liệu truy vấn.
Nhưng điều gì sẽ xảy ra nếu việc truy xuất thông tin bên ngoài hệ thống là không thể? Giả sử bạn đang giải quyết vấn đề phân loại tài liệu pháp lý nhưng không được phép gửi bất kỳ dữ liệu nào tới API bên ngoài. Trong tình huống này, bạn sẽ cần đào tạo một mô hình cục bộ nhỏ để giải quyết. Tuy nhiên, việc thu thập dữ liệu có thể trở thành một trở ngại đáng kể, gây ra sự chậm trễ trong quá trình phát triển sản phẩm.
Để đơn giản và dễ hiểu hơn, giả sử mục tiêu của chúng ta là tạo ra những câu chuyện nhỏ dành cho trẻ em. Nhiệm vụ này là điểm khởi đầu cho nghiên cứu của Eldan et al. (2023) tại Microsoft Research. Mỗi câu chuyện bao gồm 2-3 đoạn theo một cốt truyện và chủ đề đơn giản với tập dữ liệu bao gồm từ vựng và kiến thức thực tế của trẻ.
Ngôn ngữ không chỉ là một hệ thống các quy tắc và biểu tượng; nó truyền tải và giải thích ý nghĩa. Thách thức chính của việc sử dụng các mô hình ngôn ngữ lớn để tạo ra dữ liệu huấn luyện là đảm bảo tính đa dạng của tập dữ liệu. Ngay cả khi sử dụng chỉ số nhiệt K ở mức cao, các mô hình vẫn có thể tạo ra các tập dữ liệu lặp đi lặp lại làm giảm đi tính đa dạng cần thiết (ngay cả đối với ngôn ngữ của trẻ). Yêu cầu tạo dữ liệu mạch lạc và phù hợp (với trẻ, trong nghiên cứu của Eldan và cộng sự) là những thách thức khác trong việc tạo ra ngôn ngữ tự nhiên.
Để giải quyết vấn đề đa dạng, các tác giả (Eldan và cộng sự) đã chuẩn bị vốn từ vựng khoảng 1500 từ cơ bản, phản ánh vốn từ vựng điển hình của một đứa trẻ, được chia thành danh từ, động từ và tính từ. Ở mỗi một lượt tạo sinh, một động từ, một danh từ và một tính từ được chọn ngẫu nhiên. Sau đó, mô hình sẽ tạo ra một câu chuyện tích hợp những từ ngẫu nhiên này.
Kỹ thuật này đã mở rộng đáng kể tính đa dạng của tập dữ liệu, đảm bảo các câu chuyện bao gồm toàn bộ từ vựng và sự kết hợp khái niệm đa dạng của trẻ. Ngoài ra, các tác giả đã tích hợp các tính năng tiềm năng của câu chuyện (như đối thoại, tình tiết khúc mắc, kết thúc tồi tệ hoặc bài học đạo đức). Một tập hợp con ngẫu nhiên của các tính năng này đã được chọn cho mỗi câu chuyện và mô hình được nhắc đưa chúng vào.
Lời nhắc:
Write a short story (3-5 paragraphs) which only uses very simple words that a 3 year old child would likely understand. The story should use the verb ”{random.choice(verbs_list)}”, the noun ”{random.choice(nouns_list)}” and the adjective ”{random.choice(adjectives_list)}”. The story should have the following features: {random.choice(features_list)}, {random.choice(features_list)}. Remember to only use simple words!Giả sử sau khi các tham biến nhận giá trị thì ta sẽ có:
Lời nhắc:
Write a short story (3-5 paragraphs) which only uses very simple words that a 3 year old child would likely understand. The story should use the verb ”decorate”, the noun ”thunder” and the adjective ”ancient”. The story should have the following features: the story should contain at least one dialogue, the story has a bad ending. Remember to only use simple words!Đầu ra:
Once upon a time, in an ancient house, there lived a girl named Lily. She loved to decorate her room with pretty things. One day, she found a big box in the attic. She opened it and saw many shiny decorations. Lily was very happy and decided to use them in her room. As Lily was decorating her room, the sky outside became dark. There was a loud thunder sound, and Lily got scared. She ran to her mom and said, ”Mommy, the thunder is so loud!” Her mom hugged her and said, ”Don’t worry, it will pass soon.” But the thunder did not stop. It got louder and louder, and the ancient house started to shake. Suddenly, the roof fell down on the pretty decorations. Lily was sad because her room was not pretty anymore. The end.Ở đây, chúng ta dựa vào các mô hình tạo văn bản mới nhất (GPT-3.5 và GPT-4), có thể tạo ra lượng lớn nội dung tổng hợp theo hướng dẫn. Vì chúng tôi đưa ra lời nhắc một cách ngẫu nhiên mỗi lần và mô hình tuân thủ chính xác nên các câu chuyện trở nên vô cùng đa dạng. Câu chuyện sẽ hoàn toàn khác ngay cả khi một hoặc hai từ vẫn giữ nguyên. Về bản chất, chúng tôi áp dụng kỹ thuật này để đưa tính ngẫu nhiên vào lời nhắc, tạo ra một tập dữ liệu đa dạng.
Bạn hiểu ý:
- Xác định tham số/thực thể nào có thể khác nhau giữa các mẫu khác nhau trong tập dữ liệu tổng hợp của bạn;
- Tạo hoặc biên dịch thủ công một bộ sưu tập các thực thể này để lấp đầy các biến số;
- Tạo tập dữ liệu bằng cách chọn ngẫu nhiên các thực thể để chèn. Tốt nhất nên đặt chỉ số k cao hơn mặc định nhưng dưới mức tối đa;
- Huấn luyện mô hình cục bộ từ kết quả do ChatGPT/GPT-4 tạo ra.
Điều quan trọng cần lưu ý là một trong những thực thể cần tạo sinh của bạn có thể là nhãn phân loại. Ví dụ: trong nhiệm vụ phân loại cảm tính, bạn có thể đề cập trực tiếp đến “tích cực” hoặc “tiêu cực” trong lời nhắc để nhận văn bản được tạo có nhãn tương ứng. Sau đó, một bộ phân loại cục bộ được đào tạo về dữ liệu này.
Tạo dữ liệu tổng hợp kế thừa
Trong trường hợp này dạng dữ liệu có thể được thực hiện phức tạp hơn bằng cách sử dụng nhiều thực thể hơn, một số thực thể được tạo trước bởi chính LLM. Ví dụ: người ta có thể bắt đầu bằng yêu cầu tạo một bản tóm tắt câu chuyện và viết ra một câu phải xuất hiện trong câu chuyện. Sau đó, chỉ cần sử dụng dữ liệu trung gian đã tạo đó trong yêu cầu cuối cùng.
Lời nhắc:
Summary: {a short summary generated by LLM, using the approach above}
Features: {copy the features from the initial prompt}
Sentence: {a sentence generated by LLM, which should be present in the story}
Words: {copy the words from the initial prompt}
Story:Ví dụ về lời nhắc sau khi điền đủ thông tin:
Lời nhắc:
Summary: Lily and Timmy build a sandcastle together and learn to compromise, but it gets knocked over by a gust of wind. They find beauty in the broken sandcastle and play happily with a butterfly.
Features: Dialogue, Foreshadowing, Twist
Sentence: One day, she went to the park and saw a beautiful butterfly.
Words: disagree, network, beautiful
Story:Đầu ra:
Once upon a time, there was a little girl named Lily. She loved to play with her toys and her friends. One day, she went to the park and saw a beautiful butterfly. She tried to catch it, but it flew away. Lily’s friend, Timmy, came to play with her. They decided to build a sandcastle, but they disagreed on how to build it. Lily wanted to make it tall, while Timmy wanted to make it wide. They argued for a while, but finally agreed to make it both tall and wide. As they were building the sandcastle, they noticed a group of ants working together. They realized that the ants were building a network of tunnels. Suddenly, a gust of wind came and knocked over their sandcastle. They were sad, but then they saw the butterfly again. It landed on the remains of their sandcastle and they realized that it was still beautiful, even in its broken state. They smiled and played together happily.Có thể tạo ra hàng trăm nghìn ví dụ rất đa dạng để huấn luyện mô hình riêng của mình. Giả sử bạn cần đào tạo một trình phân loại để xác định xem một văn bản có chứa đoạn hội thoại hay tình tiết xoắn ốc hay không. Vì lời nhắc ban đầu có chứa các nhãn nên bạn có thể biết giá trị mục tiêu nào cần được dự đoán cho mỗi mẫu được tạo.
Tài liệu học là tất cả những gì bạn cần
Một câu hỏi quan trọng đặt ra từ phương pháp này là liệu việc tổng hợp một tập dữ liệu có thể thực sự mang lại lợi ích khi huấn luyện cho các ứng dụng thực tế hay không. May mắn thay, các tác giả đã giải quyết câu hỏi này bằng cách tiến hành nghiên cứu và xác nhận hiệu quả của việc huấn luyện các mô hình ngôn ngữ nhỏ hơn sử dụng dữ liệu tổng hợp từ các Mô hình Ngôn ngữ lớn hàng đầu.
Trong nghiên cứu của mình, Gunasekar và cộng sự (2023) nhấn mạnh tầm quan trọng của dữ liệu huấn luyện chất lượng cao trong mô hình của họ. Họ cho rằng các mô hình ngôn ngữ sẽ hiệu quả hơn nếu chúng được huấn luyện trên các tài liệu có đặc điểm giống như một “giáo trình” được đánh giá cao: rõ ràng, toàn diện, thông tin và không thiên vị.
Các nguyên tắc này đã hình thành cơ sở để tạo ra một tập dữ liệu bán tổng hợp để huấn luyện LLM gọi là Phi-1. Nhiệm vụ đánh giá chính là tạo ra một hàm Python tuân theo mô tả văn bản hoặc docstring cho sẵn. Chất lượng của mô hình được đánh giá bằng tiêu chuẩn HumanEval (Chen et al., 2021).
Các tác giả nhấn mạnh tầm quan trọng của sự đa dạng trong phương pháp này vì nhiều lý do. Nó giúp mô hình ngôn ngữ tiếp xúc với nhiều biểu thức mã hóa và cách tiếp cận giải quyết vấn đề khác nhau, giảm nguy cơ quá khớp hoặc phụ thuộc vào các mẫu cụ thể, và cải thiện khả năng của mô hình trong việc xử lý các nhiệm vụ lạ hoặc sáng tạo.
Để giải quyết thách thức viết mã, các tác giả đã tạo ra các tài liệu giống như giáo trình tập trung vào các chủ đề khuyến khích tư duy và kỹ năng thuật toán cơ bản. Họ đã đạt được sự đa dạng bằng cách áp đặt các hạn chế lên:
- Các chủ đề
- Đối tượng mục tiêu
Các tác giả không cung cấp thông tin cụ thể về mẫu prompt được sử dụng để tạo dữ liệu tổng hợp. Tuy nhiên, họ đã trình bày kết quả đầu ra. Họ chọn sử dụng ChatGPT (GPT-3.5) thay vì GPT-4, và ngay cả chiến lược này cũng mang lại kết quả xuất sắc khi họ tinh chỉnh mô hình sử dụng dữ liệu tổng hợp.

Một điểm quan trọng cần lưu ý là hạn chế đối tượng mục tiêu. Việc chỉ định một đối tượng mục tiêu là một cách tuyệt vời để nâng cao sự đa dạng của dữ liệu tổng hợp. Một học sinh trung học, một sinh viên đại học ngành Khoa học Máy tính, và một nghiên cứu sinh tiến sĩ chắc chắn sẽ diễn đạt giải thích và xử lý thông tin khác nhau, làm cho dữ liệu tạo ra phong phú hơn. Hãy thử tạo lại prompt này.
Prompt:
Viết một đoạn trích từ một giáo trình Khoa học Máy tính cho sinh viên năm nhất. Ngôn ngữ lập trình là Python 3.6.
Đây là một đoạn trích từ giữa của chủ đề: Ma trận kỳ dị.
Đoạn trích bắt đầu bằng một tổng quan ở cấp cao về chủ đề.
Sau đó, nó trình bày một ví dụ và mô tả giải pháp bằng ngôn ngữ tự nhiên. Sau đó, nó cung cấp 1-2 đoạn mã, theo sau ví dụ.
Mỗi đoạn mã không quá 10 dòng. Không nên có văn bản sau các đoạn mã.
Lưu ý rằng đoạn trích nên ngắn gọn và chỉ giải thích một khái niệm tại một thời điểm. Mã nên đại diện cho một hàm Python và cách gọi của nó. Tất cả các thư viện ML/DS phổ biến đều có sẵn.
Đừng quá dài dòng. Độ dài dự kiến của đoạn trích là không quá 2 đoạn.Output:
**Ma trận Kỳ Dị**
Trong đại số tuyến tính, một ma trận được gọi là "kỳ dị" nếu nó không có nghịch đảo. Một định nghĩa tương đương khác là khi định thức của ma trận bằng không. Ma trận kỳ dị rất quan trọng vì chúng đại diện cho các hệ phương trình tuyến tính không có nghiệm duy nhất.
Xem xét một ma trận 2x2 [[a, b], [c, d]]. Nếu tích của ad và bc bằng nhau (tức là ad = bc), thì ma trận này là kỳ dị. Hãy khám phá điều này với một ví dụ: cho ma trận [[2, 4], [1, 2]], bạn sẽ thấy rằng tích của các đường chéo cho cùng kết quả (2 * 2 = 4 * 1), do đó nó là ma trận kỳ dị.
import numpy as np
def is_singular(matrix):
determinant = np.linalg.det(matrix)
return abs(determinant) < 1e-9
matrix_example = np.array([[2, 4], [1, 2]])
print(is_singular(matrix_example)) # returns True
Gần đúng!
Tổng cộng, các tác giả đã tạo ra 1 tỷ tokens để bổ sung vào tập huấn luyện của mô hình, cho phép một mô hình nhỏ hơn (chỉ 1.5 tỷ tham số) có thể cạnh tranh với các mô hình lớn hơn mười lần (để biết chi tiết, tham khảo bài viết của Gunasekar et al. (2023)).
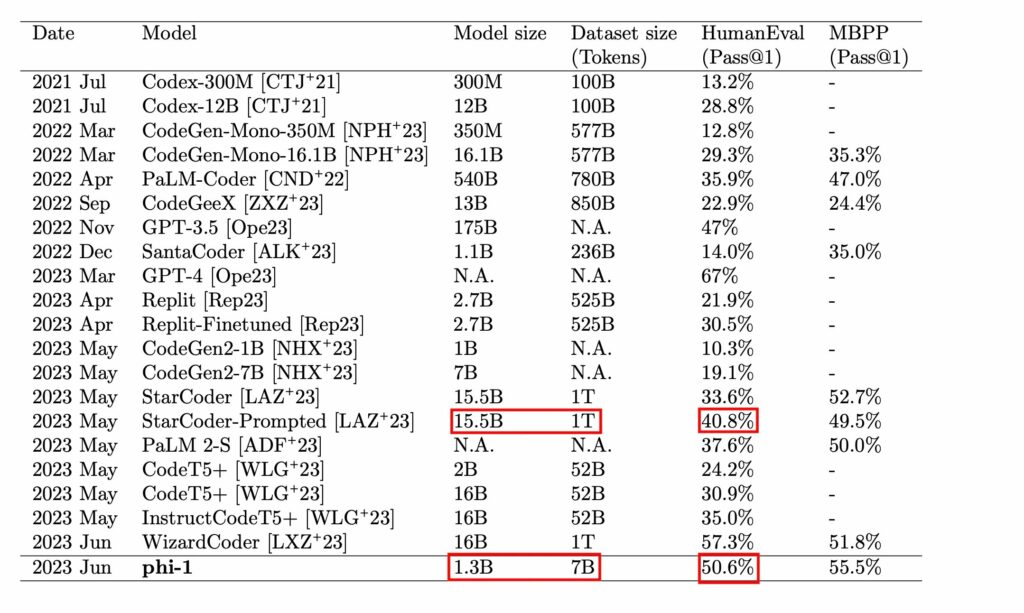
Đối với nhiệm vụ của bạn, có lẽ bạn sẽ không cần một lượng lớn dữ liệu tổng hợp như vậy (vì các tác giả đã nghiên cứu việc tiền huấn luyện, điều này đòi hỏi nhiều tài nguyên). Tuy nhiên, ngay cả ước tính, với giá $0.002 cho mỗi 1k tokens (giá chuẩn của ChatGPT), sẽ tốn $2000 cho số tokens tạo ra và khoảng số tiền tương tự cho các prompts.
Hãy nhớ rằng việc tinh chỉnh trên dữ liệu tổng hợp trở nên có giá trị hơn khi được áp dụng vào các lĩnh vực riêng để trở nên chuyên biệt hơn, đặc biệt nếu ngôn ngữ khác với tiếng Anh. Ngoài ra, phương pháp này hoạt động tốt với kỹ thuật Chuỗi Tư Duy (Chain-of-Thought – CoT), giúp cải thiện khả năng tư duy của mô hình cục bộ. Các kỹ thuật prompt khác cũng hoạt động tốt. Và đừng quên rằng các mô hình mã nguồn mở như Alpaca (Taori và cộng sự, 2023) và Vicuna (Zheng và cộng sự, 2023) đều xuất sắc thông qua việc tinh chỉnh trên dữ liệu tổng hợp.