

Tác giả: Aruna Pattam
Chào mừng bạn đến với thế giới phức tạp của Mô hình Ngôn ngữ (LMs), nơi kích thước của mô hình có thể ảnh hưởng đáng kể đến khả năng và ứng dụng của nó.
Trong bài đăng này, tôi sẽ đào sâu vào lĩnh vực của Mô hình Ngôn ngữ Lớn và Nhỏ, khám phá các đặc điểm đặc trưng và vai trò của chúng trong cảnh quan trí tuệ nhân tạo ngày càng phát triển.
Sự Tiến Hóa của Mô hình Ngôn ngữ: Một Quan điểm Lịch sử
Quá trình tiến hóa của các mô hình ngôn ngữ đã biến đổi đáng kể lĩnh vực Trí tuệ Nhân tạo và xử lý ngôn ngữ tự nhiên. Chuyển từ các hệ thống dựa trên quy tắc cơ bản đến các mạng nơ-ron tiên tiến, những mô hình này hiện tạo ra văn bản phong phú ngữ cảnh nhờ vào sức mạnh tính toán gia tăng và các bộ dữ liệu văn bản lớn. Sự tích hợp của chúng vào các nền tảng thân thiện với người dùng đã làm cho chúng trở nên dễ tiếp cận với tất cả mọi người.
Dưới đây là một số cột mốc quan trọng trong sự tiến hóa của các mô hình ngôn ngữ:
Phát triển Sớm trong Mô hình Ngôn ngữ:
Quá trình tiến triển của các mô hình ngôn ngữ có thể được truy ngược về thập kỷ 1950, bắt đầu với các hệ thống dựa trên quy tắc nguyên tắc. Những mô hình sớm, như chương trình “ELIZA” được tạo ra vào năm 1966, là đột phá nhưng hạn chế, phụ thuộc vào các mô hình mẫu được xác định trước mà không thực sự nắm bắt được sự tinh tế của ngôn ngữ.
Sự Xuất Hiện của Mô hình Ngôn ngữ Lớn (LLMs)

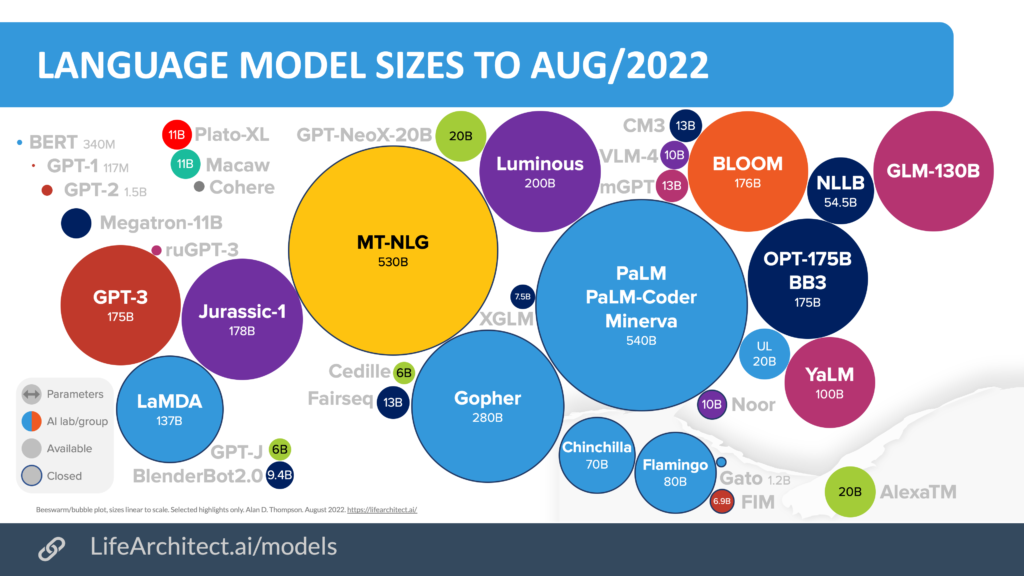
Một sự chuyển đổi quan trọng đã xảy ra vào những năm 2010 với sự xuất hiện của các Mô hình Ngôn ngữ Lớn (LLMs) như GPT-3 và BERT. Những mô hình này, tận dụng các tiến bộ trong sức mạnh tính toán và ngữ liệu văn bản rộng lớn, có thể tạo ra văn bản mạch lạc, phù hợp với ngữ cảnh. Chúng đánh dấu một bước tiến đáng kể trong xử lý ngôn ngữ, tìm thấy ứng dụng trong các chatbot, dịch ngôn ngữ và tạo nội dung. Đến năm 2022, tác động của LLMs đã rõ ràng, với một phần đáng kể của lực lượng lao động xem xét hoặc triển khai Trí tuệ Nhân tạo Sinh sáng dựa trên những mô hình này.
Xu hướng Gần đây trong Mô hình Ngôn ngữ Nhỏ (SLMs):
Xu hướng mới nhất trong dòng thời gian tiến hóa này là sự phát triển của Mô hình Ngôn ngữ Nhỏ (SLMs). Xuất hiện vào cuối những năm 2010 và trở nên quan trọng vào năm 2023 với các mô hình như TinyBERT của Google, SLMs được thiết kế để hiệu quả. Chúng là lựa chọn lý tưởng cho triển khai trên các thiết bị có tài nguyên hạn chế, duy trì hiệu suất cao trong khi được huấn luyện trên các bộ dữ liệu nhỏ hơn. Sự chuyển đổi này hướng đến SLMs phản ánh sự tập trung ngày càng lớn đến việc tạo ra các giải pháp Trí tuệ Nhân tạo dễ tiếp cận, bền vững, thể hiện tính động và không ngừng phát triển của các mô hình ngôn ngữ.
Hiểu về Mô hình Ngôn ngữ Lớn và Nhỏ
Mô hình Ngôn ngữ Lớn (LLMs)
LLMs là những mô hình Trí tuệ Nhân tạo tiên tiến được thiết kế để hiểu, diễn giải và tạo ra ngôn ngữ con người. Chúng được đặc trưng bởi việc được huấn luyện mạnh mẽ trên các bộ dữ liệu rộng lớn và kiến trúc mạng nơ-ron sâu của chúng. Ví dụ bao gồm GPT-3 và BERT. LLMs xuất sắc trong việc tạo ra văn bản mạch lạc, phù hợp với ngữ cảnh và được sử dụng trong các ứng dụng đòi hỏi xử lý ngôn ngữ phức tạp.
Mô hình Ngôn ngữ Nhỏ (SLMs)
SLMs là những phiên bản nhỏ gọn hơn của các mô hình ngôn ngữ, được thiết kế để hiệu quả và linh hoạt. Chúng được huấn luyện trên các bộ dữ liệu nhỏ hơn và được tối ưu hóa cho hiệu suất trong môi trường có tài nguyên tính toán hạn chế. SLMs như TinyBERT và DistilBERT, mặc dù không mạnh mẽ bằng LLMs, vẫn hiệu quả trong các nhiệm vụ xử lý ngôn ngữ và lý tưởng cho ứng dụng di động và IoT.
Sự Khác Biệt Giữa LLMs và SLMs

#1: Kích Thước và Phức Tạp:
Các Mô hình Ngôn ngữ Lớn (LLMs), như GPT-4, tự hào với các kiến trúc rộng lớn và phức tạp, bao gồm các mạng nơ-ron sâu với hàng tỷ tham số, cung cấp khả năng hiểu và tạo ra ngôn ngữ tiên tiến.
Ngược lại, Mô hình Ngôn ngữ Nhỏ (SLMs) được thiết kế với ít tham số hơn, khiến chúng trở nên linh hoạt và hiệu quả hơn, nhưng có khả năng xử lý ngôn ngữ hạn chế hơn so với LLMs.
#2: Yêu Cầu Huấn Luyện và Dữ Liệu
Các Mô hình Ngôn ngữ Lớn (LLMs) đòi hỏi việc huấn luyện trên các bộ dữ liệu lớn và đa dạng, bao gồm nhiều loại văn bản để có khả năng hiểu ngôn ngữ một cách toàn diện.
Ngược lại, Mô hình Ngôn ngữ Nhỏ (SLMs) được huấn luyện trên các bộ dữ liệu hạn chế hơn, được tùy chỉnh cho các nhiệm vụ cụ thể hoặc ít toàn diện hơn, dẫn đến một cơ sở kiến thức và khả năng ngôn ngữ tập trung hơn nhưng ít đa dạng hóa.
#3: Khả Năng Xử Lý Ngôn Ngữ Tự Nhiên và Tiếp Xúc Ngôn Ngữ
Các Mô hình Ngôn ngữ Lớn (LLMs) thể hiện khả năng xử lý ngôn ngữ tự nhiên (NLP) xuất sắc, đã được tiếp xúc với nhiều mẫu ngôn ngữ, giúp chúng có khả năng hiểu và tạo ra ngôn ngữ một cách tinh tế.
Ngược lại, Mô hình Ngôn ngữ Nhỏ (SLMs) có khả năng và tiếp xúc NLP hạn chế hơn, dẫn đến một phạm vi hiểu biết và ứng dụng ngôn ngữ hẹp hơn.
#4: Yêu Cầu Tính Toán và Triển Khai

Các Mô hình Ngôn ngữ Lớn (LLMs) đòi hỏi tài nguyên tính toán đáng kể, làm cho chúng phù hợp cho môi trường yêu cầu công suất và tài nguyên cao. Chúng yêu cầu phần cứng tiên tiến để hoạt động một cách tối ưu.
Ngược lại, Mô hình Ngôn ngữ Nhỏ (SLMs) được tùy chỉnh cho cài đặt tài nguyên thấp, cung cấp một giải pháp thực tế hơn cho các môi trường có khả năng tính toán hạn chế, đảm bảo sự tiếp cận rộng rãi và dễ triển khai.
#5: Hiệu Suất và Hiệu Quả
Các Mô hình Ngôn ngữ Lớn (LLMs) xuất sắc về độ chính xác và xử lý các nhiệm vụ phức tạp, nhưng kích thước và phức tạp của chúng làm cho chúng ít hiệu quả về mặt tính toán và sử dụng năng lượng.
Mô hình Ngôn ngữ Nhỏ (SLMs), mặc dù có thể ít thành thạo hơn ở các nhiệm vụ phức tạp và có thể thấp hơn về hiệu suất tổng, nhưng đáng kể hiệu quả hơn, đặc biệt là đối với năng lượng và tài nguyên tính toán.
#6: Ứng Dụng và Điểm Mạnh
Các Mô hình Ngôn ngữ Lớn (LLMs) lý tưởng cho các nhiệm vụ NLP tiên tiến như dịch máy, tóm tắt văn bản, tạo nội dung và chatbot phức tạp, xuất sắc trong các nhiệm vụ ngôn ngữ phức tạp và tạo văn bản sáng tạo.
Mô hình Ngôn ngữ Nhỏ (SLMs) phù hợp hơn cho ứng dụng di động, thiết bị IoT và các môi trường có tài nguyên hạn, mang lại yêu cầu tính toán giảm và chi phí triển khai thấp, lý tưởng cho các ứng dụng edge computing.
#7: Tính Tùy Chỉnh, Thích ứng và Tiếp Cận
Các Mô hình Ngôn ngữ Lớn (LLMs) đòi hỏi nhiều tài nguyên cho việc tùy chỉnh và ít thích ứng với các ứng dụng quy mô nhỏ, thường cần phần cứng chuyên dụng hoặc tính toán đám mây.
Ngược lại, Mô hình Ngôn ngữ Nhỏ (SLMs) dễ tùy chỉnh và thích ứng hơn cho các ứng dụng cụ thể và nhỏ hơn, có thể triển khai hiệu quả trên phần cứng và thiết bị tiêu chuẩn, tăng cường khả năng tiếp cận.
#8: Chi Phí và Tiềm Năng Tác Động
Các Mô hình Ngôn ngữ Lớn (LLMs) gây ra chi phí vận hành và phát triển cao hơn, nhưng khả năng tự động hóa các nhiệm vụ phức tạp, cải thiện giao tiếp và tăng cường sự sáng tạo mang lại tác động lớn.
Mô hình Ngôn ngữ Nhỏ (SLMs), với chi phí vận hành và phát triển thấp hơn, làm cho công nghệ Trí tuệ Nhân tạo trở nên phổ cập hóa, làm cho xử lý ngôn ngữ thông minh trở nên dễ tiếp cận đối với một đối tượng người dùng rộng lớn.
#9: Sở Hữu Trí Tuệ và An Ninh
Các Mô hình Ngôn ngữ Lớn (LLMs) đối mặt với các vấn đề phức tạp về sở hữu trí tuệ (IP) do quy mô rộng lớn của dữ liệu và quá trình huấn luyện, và có thể có rủi ro an ninh cao hơn với các bề mặt tấn công lớn.
Mô hình Ngôn ngữ Nhỏ (SLMs), với quy mô dữ liệu và quá trình huấn luyện nhỏ hơn, có một quang cảnh sở hữu trí tuệ đơn giản hóa và các bề mặt tấn công nhỏ hơn, có thể mang lại sự an toàn nâng cao trong một số ngữ cảnh.
#10: Các Kỹ Thuật Nổi Bật
Các Mô hình Ngôn ngữ Lớn (LLMs) đang ở vị thế hàng đầu trong nghiên cứu Trí tuệ Nhân tạo, liên tục tiến triển với những đổi mới mới, được minh họa bởi các mô hình như GPT-3, LlaMA, Falcon, v.v.
Mô hình Ngôn ngữ Nhỏ (SLMs) nhanh chóng thích nghi với các phương pháp Trí tuệ Nhân tạo mới, hiệu quả cho môi trường nhỏ gọn, với ví dụ như DistilBERT, Orca 2, GPT-Neo, v.v.
Các Ví Dụ và Ứng Dụng của Các Mô hình Ngôn ngữ Lớn (LLMs)
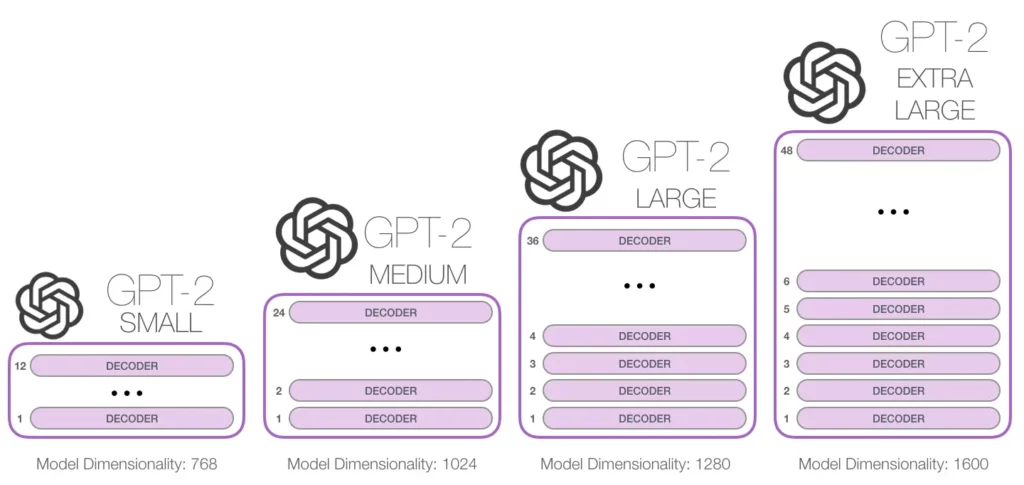
GPT-4: GPT-4, là một trí tuệ nhân tạo sinh sáng mới nhất của OpenAI, vượt trội hơn so với GPT-3.5 với khả năng xử lý ngôn ngữ và đa phương tiện tiên tiến. Được huấn luyện trên một nghìn tỷ tham số, nó xuất sắc trong việc tạo ra văn bản, hiểu hình ảnh và video, đồng thời cải thiện đáng kể việc tạo nội dung trang web, tối ưu hóa SEO, và chiến lược tiếp thị tương tác.
LlaMA: LlaMA, là một Mô hình Ngôn ngữ Lớn nguồn mở của Meta AI, xuất sắc trong việc giải quyết câu hỏi, hiểu ngôn ngữ và đọc. Thiết kế của nó nhắm vào các ứng dụng giáo dục, biến nó thành một trợ lý Trí tuệ Nhân tạo xuất sắc cho các nền tảng Edtech, nâng cao trải nghiệm học tập với khả năng học ngôn ngữ tiên tiến.
Falcon: Falcon, do Viện Công nghệ Đổi mới sản xuất, là một mô hình ngôn ngữ tự nhiên nguồn mở, autoregressive, vượt trội hơn so với LlaMA về hiệu suất. Với một bộ dữ liệu văn bản và mã nguồn đa dạng, kiến trúc tiên tiến và xử lý dữ liệu hiệu quả, nó xuất sắc với ít tham số hơn (40 tỷ) so với các mô hình NLP hàng đầu.
Cohere: Cohere, được phát triển bởi một công ty khởi nghiệp Canada, là một Mô hình Ngôn ngữ Lớn nguồn mở, đa ngôn ngữ được huấn luyện trên một bộ dữ liệu toàn diện. Hiệu quả của nó trên nhiều ngôn ngữ và giọng địa phương đến từ việc được huấn luyện trên một ngữ liệu văn bản đa dạng và lớn, tạo ra tính linh hoạt cho nhiều loại nhiệm vụ.
PaLM: PaLM của Google AI, là một Mô hình Ngôn ngữ Lớn mới nổi, tận dụng bộ dữ liệu phong phú của Google để hiểu ngôn ngữ, tạo ra phản ứng, dịch máy và nhiệm vụ sáng tạo tiên tiến. Đặt nặng vào quyền riêng tư và bảo mật, nó lý tưởng cho thương mại điện tử an toàn và xử lý thông tin nhạy cảm, thể hiện sự đột phá trong lĩnh vực Trí tuệ Nhân tạo có trách nhiệm.
Các mô hình ngôn ngữ nhỏ (Small Language Models)
DistilBERT: DistilBERT, do Hugging Face phát triển, là một mô hình Transformer nhỏ gọn, nhẹ hơn 40% và nhanh hơn 60% so với BERT, với hiệu suất mạnh mẽ. Nó lý tưởng cho các chatbot, kiểm duyệt nội dung và tích hợp ứng dụng di động.
Orca 2: Orca 2, mô hình nhỏ gọn của Microsoft với 7 và 13 tỷ tham số, xuất sắc trong việc luận lý và vượt trội hơn so với các mô hình lớn hơn. Nó được sử dụng cho phân tích dữ liệu, hiểu biết, giải toán và tóm tắt.
T5-Small: T5-Small quản lý một cách hiệu quả việc tóm tắt văn bản, phân loại và dịch, lý tưởng cho các cài đặt nguồn lực vừa như máy chủ nhỏ và ứng dụng đám mây, mang lại khả năng xử lý ngôn ngữ tự nhiên mạnh mẽ mà không đòi hỏi tài nguyên tính toán cao.
RoBERTa: RoBERTa, một sự cải tiến của BERT, xuất sắc với quá trình huấn luyện tiên tiến và lượng dữ liệu lớn hơn. Nó được sử dụng để hiểu ngôn ngữ sâu sắc, kiểm duyệt nội dung và phân tích các bộ dữ liệu lớn một cách hiệu quả.
Phi 2: Phi 2 của Microsoft là một Mô hình Ngôn ngữ Nhỏ đa năng, dựa trên transformer, được tối ưu hóa cho cả tính toán đám mây và tính toán ở cạnh. Nó đạt được hiệu suất hàng đầu trong luận lý toán học, đánh giá lập luận thông thường, hiểu ngôn ngữ và tư duy logic, thể hiện tính hiệu quả và tính thích ứng của nó.
Kết Luận

Bức tranh về Mô hình Ngôn ngữ là một lĩnh vực động và đang phát triển, với cả Mô hình Ngôn ngữ Lớn và Nhỏ đều đóng vai trò quan trọng. Các Mô hình Ngôn ngữ Lớn (LLMs) như GPT-4 và LlaMA tiếp tục định nghĩa lại giới hạn của Trí tuệ Nhân tạo với khả năng đồ sộ của chúng trong hiểu và tạo ngôn ngữ. Trong khi đó, các Mô hình Ngôn ngữ Nhỏ (SLMs) như DistilBERT và Orca 2 mang lại hiệu suất và tính thích ứng, làm cho Trí tuệ Nhân tạo trở nên tiếp cận trong môi trường có tài nguyên hạn chế.
Khi chúng ta chào đón công nghệ phát triển nhanh chóng này, việc ở trong tình trạng thông tin và tương tác là rất quan trọng. Cho dù bạn là một nhà phát triển, người lãnh đạo doanh nghiệp, giáo viên hay người tò mò, việc khám phá tiềm năng của LLMs và SLMs là chìa khóa.
Hãy tiếp tục thử nghiệm, học hỏi và xem xét về những tác động đạo đức khi chúng ta điều hướng trong thời đại hứng thú của Trí tuệ Nhân tạo. Hành trình khám phá và đổi mới trong các mô hình ngôn ngữ chỉ mới bắt đầu, và sự tham gia của bạn là quan trọng để định hình tương lai của chúng.