

Zhang và cộng sự. (2023) gần đây đã đề xuất một phương pháp thúc đẩy chuỗi suy nghĩ đa phương thức. CoT truyền thống tập trung vào ngôn ngữ. Ngược lại, CoT đa phương thức kết hợp văn bản và thị giác vào một framework hai giai đoạn. Bước đầu tiên liên quan đến việc tạo cơ sở lý luận dựa trên thông tin đa phương thức. Tiếp theo là giai đoạn thứ hai, suy luận câu trả lời, thúc đẩy các cơ sở lý luận được tạo ra mang tính thông tin.
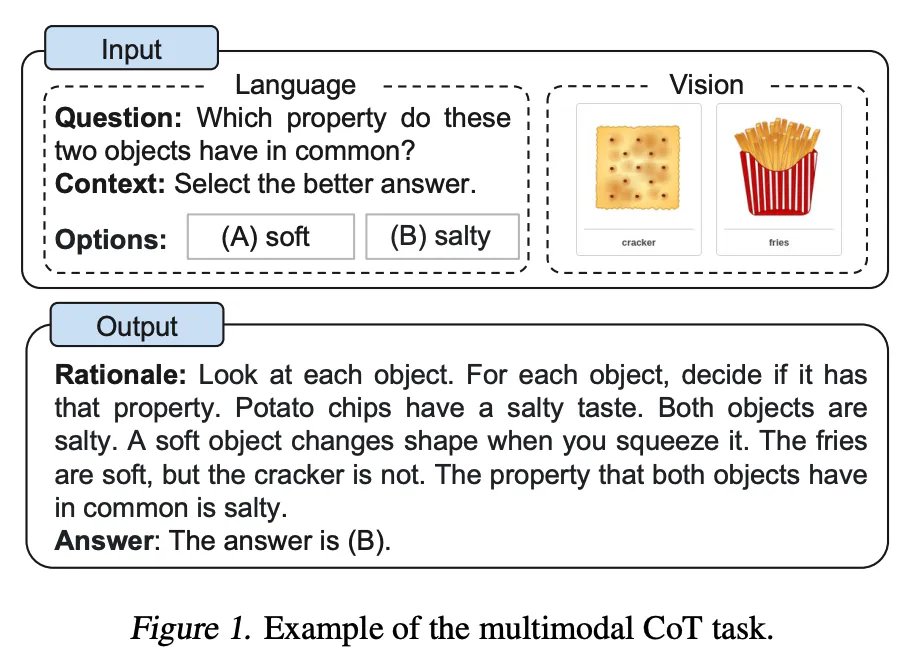
Hình ảnh trên minh họa cho nhiệm vụ Multimodal CoT (Chain of Thought) Prompting, trong đó mô hình phải xử lý thông tin từ cả ngôn ngữ và hình ảnh để đưa ra câu trả lời chính xác. Dưới đây là giải thích chi tiết về từng phần của hình ảnh và cách hoạt động của kỹ thuật này:
Các thành phần chính của hình ảnh:
- Input (Đầu vào):
- Language (Ngôn ngữ): Đây là phần chứa câu hỏi và ngữ cảnh. Câu hỏi yêu cầu xác định đặc tính chung giữa hai đối tượng hiển thị trong hình ảnh. Cụ thể:
- Question: “Which property do these two objects have in common?” (Đặc tính nào mà hai đối tượng này có chung?)
- Context: “Select the better answer.” (Chọn câu trả lời đúng nhất)
- Options: (A) soft (mềm), (B) salty (mặn)
- Vision (Hình ảnh): Đây là phần chứa hình ảnh của hai đối tượng cần được so sánh:
- Cracker (bánh quy giòn)
- Fries (khoai tây chiên)
- Language (Ngôn ngữ): Đây là phần chứa câu hỏi và ngữ cảnh. Câu hỏi yêu cầu xác định đặc tính chung giữa hai đối tượng hiển thị trong hình ảnh. Cụ thể:
- Output (Đầu ra):
- Rationale (Lý do): Phần này giải thích quá trình suy nghĩ và lý luận để đi đến kết luận cuối cùng. Đây là chuỗi suy nghĩ (Chain of Thought) giúp mô hình từng bước phân tích và so sánh các đối tượng:
- “Look at each object. For each object, decide if it has that property. Potato chips have a salty taste. Both objects are salty. A soft object changes shape when you squeeze it. The fries are soft, but the cracker is not. The property that both objects have in common is salty.”
- Dịch: “Nhìn vào từng đối tượng. Với mỗi đối tượng, xác định xem nó có đặc tính đó không. Khoai tây chiên có vị mặn. Cả hai đối tượng đều mặn. Một đối tượng mềm sẽ thay đổi hình dạng khi bạn bóp nó. Khoai tây chiên mềm, nhưng bánh quy giòn thì không. Đặc tính mà cả hai đối tượng có chung là mặn.”
- Answer (Câu trả lời): Câu trả lời cuối cùng sau khi đã phân tích:
- “The answer is (B).” (Câu trả lời là (B))
- Rationale (Lý do): Phần này giải thích quá trình suy nghĩ và lý luận để đi đến kết luận cuối cùng. Đây là chuỗi suy nghĩ (Chain of Thought) giúp mô hình từng bước phân tích và so sánh các đối tượng:
Quy trình hoạt động của Multimodal CoT Prompting:
- Nhận đầu vào:
- Mô hình nhận cả thông tin văn bản (ngôn ngữ) và hình ảnh.
- Phân tích và lý luận:
- Mô hình phân tích từng đối tượng trong hình ảnh và so sánh chúng dựa trên các đặc tính được cung cấp trong các tùy chọn.
- Mô hình sử dụng chuỗi suy nghĩ để giải thích lý do vì sao nó chọn một đặc tính cụ thể. Trong ví dụ này, mô hình xác định rằng khoai tây chiên và bánh quy giòn đều mặn, nhưng chỉ có khoai tây chiên là mềm.
- Đưa ra câu trả lời:
- Sau khi hoàn tất quá trình phân tích và lý luận, mô hình đưa ra câu trả lời cuối cùng, giải thích lý do và chọn đặc tính chung đúng nhất.
Kết luận
Multimodal CoT Prompting là kỹ thuật kết hợp thông tin từ nhiều nguồn (ngôn ngữ và hình ảnh) và sử dụng chuỗi suy nghĩ để đưa ra các kết luận chính xác. Trong ví dụ này, mô hình đã thành công trong việc phân tích và so sánh các đặc tính của hai đối tượng, sử dụng lý luận logic để chọn ra câu trả lời đúng, minh họa cách kỹ thuật này có thể nâng cao khả năng suy luận và hiểu biết của mô hình ngôn ngữ.