

Kỹ thuật Reflexion Prompting là một phương pháp nâng cao trong việc sử dụng mô hình ngôn ngữ lớn (LLMs) nhằm cải thiện khả năng suy luận, tự đánh giá và tự điều chỉnh của mô hình khi thực hiện các nhiệm vụ phức tạp. Reflexion giúp mô hình không chỉ đưa ra phản hồi mà còn tự xem xét lại các phản hồi của mình, học từ đó và cải thiện hiệu suất thông qua các vòng lặp tự đánh giá.
Giải thích chi tiết về Reflexion Prompting
- Mục tiêu của Reflexion Prompting:
- Tự đánh giá và cải thiện: Cho phép mô hình ngôn ngữ tự kiểm tra và đánh giá các câu trả lời của chính nó, xác định các lỗi và đưa ra các phiên bản cải thiện của câu trả lời.
- Học từ phản hồi: Tận dụng các phản hồi từ quá trình tự đánh giá để liên tục cải thiện khả năng suy luận và phản hồi.
- Cách hoạt động của Reflexion Prompting:
- Vòng lặp suy luận và đánh giá: Mô hình thực hiện nhiệm vụ và sau đó tự đánh giá câu trả lời của mình. Dựa trên đánh giá này, mô hình có thể điều chỉnh và cải thiện câu trả lời.
- Phản hồi và điều chỉnh: Mô hình sử dụng phản hồi từ quá trình đánh giá để điều chỉnh phản hồi ban đầu, cải thiện độ chính xác và tính logic của câu trả lời.
- Ví dụ về Reflexion Prompting:
Nhiệm vụ: Giải một câu đố logic:
- Câu đố: “Một người đi vào một căn phòng tối với một que diêm. Trong phòng có một cây nến, một chiếc đèn dầu và một bếp lửa. Anh ta nên thắp sáng cái nào trước?”
Prompt Cụ Thể cho Reflexion
Prompt:
Bạn là một chuyên gia giải quyết vấn đề logic. Hãy suy nghĩ và đưa ra câu trả lời cho câu đố sau. Sau khi trả lời, hãy tự đánh giá và xem xét liệu câu trả lời của bạn có hợp lý không. Nếu thấy cần thiết, hãy chỉnh sửa và cải thiện câu trả lời.
---
**Câu đố:** Một người đi vào một căn phòng tối với một que diêm. Trong phòng có một cây nến, một chiếc đèn dầu và một bếp lửa. Anh ta nên thắp sáng cái nào trước?
**Câu trả lời ban đầu:**
Kết quả Đầu ra từ Mô hình:
- Câu trả lời ban đầu:
- Người đó nên thắp sáng cây nến trước.
- Đánh giá và suy nghĩ lại:
- Đánh giá: Câu trả lời này có vẻ hợp lý, nhưng cần xem xét lại toàn bộ bối cảnh của câu đố.
- Suy nghĩ: Để thắp sáng cây nến, người đó cần phải sử dụng que diêm. Vậy, điều đầu tiên cần thắp sáng là que diêm.
- Câu trả lời được chỉnh sửa:
- Người đó nên thắp sáng que diêm trước.
Kết quả Cuối cùng
Câu trả lời cuối cùng:
- Người đó nên thắp sáng que diêm trước.
Lợi ích của Reflexion Prompting
- Tự kiểm tra và cải thiện: Cho phép mô hình tự đánh giá và học từ các lỗi của mình, dẫn đến việc cải thiện dần dần qua các vòng lặp tự đánh giá.
- Nâng cao độ chính xác: Việc tự đánh giá giúp mô hình phát hiện và sửa chữa các lỗi, từ đó nâng cao độ chính xác của các phản hồi.
- Tư duy phê phán: Khuyến khích mô hình phát triển khả năng tư duy phê phán, xem xét lại các giả định ban đầu và cải thiện suy luận.
Tác nhân phản xạ
Ví dụ trên là một ví dụ đơn giản được thực hiện hoàn toàn bằng mô hình ngôn ngữ, tuy nhiên trong các ứng dụng thực tế thì các yêu cầu nhiệm vụ có thể phức tạp hợp nhiều vì vậy đã có nhiều nghiên cứu được công bố dựa trên các tác nhân nhằm củng cố khả năng có thể triển khai. Theo Shinn và cộng sự. (2023), “Phản xạ là một mô hình mới để củng cố ‘bằng lời nói’ tham số hóa chính sách dưới dạng mã hóa bộ nhớ của tác nhân được song song với sự lựa chọn các tham số LLM.”
Ở cấp độ cao, phản xạ chuyển đổi phản hồi từ của chính hệ thống thành ngôn ngữ đầu vào, còn được gọi là phản ánh bản thân làm bối cảnh cho tác nhân LLM trong tập tiếp theo. Điều này giúp LLM có thể học hỏi nhanh chóng và hiệu quả từ những sai lầm trước đó, từ đó cải thiện hiệu suất trên nhiều nhiệm vụ nâng cao.
Hãy quan sát lược đồ dưới đây:
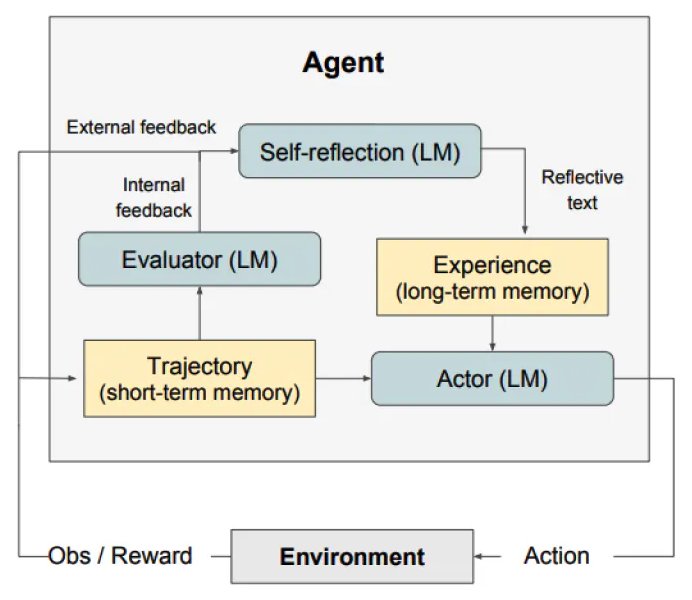
Lưu đồ trên minh họa một kiến trúc hệ thống cho một agent (tác nhân) sử dụng kỹ thuật Reflexion trong mô hình ngôn ngữ (Language Model – LM) để cải thiện hiệu suất thông qua việc tự đánh giá và học từ trải nghiệm. Dưới đây là giải thích chi tiết về từng thành phần và quy trình hoạt động của hệ thống:
Các thành phần chính:
- Self-reflection (LM):
- Đây là phần tự phản chiếu của mô hình ngôn ngữ, nơi mà tác nhân tự đánh giá và xem xét lại các hành động và phản hồi của mình. Phần này sử dụng mô hình ngôn ngữ để tạo ra văn bản phản ánh, giúp mô hình học hỏi từ trải nghiệm.
- Evaluator (LM):
- Bộ đánh giá, cũng sử dụng mô hình ngôn ngữ, để phân tích và đánh giá hiệu suất của các hành động đã thực hiện. Nó cung cấp phản hồi nội bộ để giúp tác nhân điều chỉnh hành động của mình.
- Trajectory (short-term memory):
- Bộ nhớ ngắn hạn lưu trữ các hành động và phản hồi trong một phiên làm việc hoặc một khoảng thời gian ngắn. Nó giúp theo dõi các bước đã thực hiện và kết quả đạt được.
- Experience (long-term memory):
- Bộ nhớ dài hạn lưu trữ các trải nghiệm đã được tự phản chiếu và đánh giá, giúp tác nhân học hỏi từ các trải nghiệm trong quá khứ và cải thiện hiệu suất trong tương lai.
- Actor (LM):
- Bộ thực hiện hành động, sử dụng mô hình ngôn ngữ để đưa ra các hành động dựa trên phản hồi và kinh nghiệm tích lũy. Nó tương tác trực tiếp với môi trường.
Quy trình hoạt động:
- Observation/Reward từ môi trường:
- Tác nhân nhận thông tin quan sát (Observation) và phần thưởng (Reward) từ môi trường.
- Action (Hành động):
- Bộ Actor (LM) đưa ra các hành động dựa trên thông tin quan sát và kinh nghiệm trước đó.
- Trajectory:
- Các hành động và kết quả của chúng được lưu trữ tạm thời trong bộ nhớ ngắn hạn (Trajectory).
- Evaluation (Đánh giá):
- Bộ Evaluator (LM) phân tích các hành động và kết quả, cung cấp phản hồi nội bộ về hiệu suất.
- Self-reflection:
- Bộ Self-reflection (LM) sử dụng phản hồi từ Evaluator để tạo ra văn bản phản ánh, giúp tác nhân tự đánh giá và rút kinh nghiệm.
- Experience:
- Các thông tin phản chiếu được lưu trữ trong bộ nhớ dài hạn (Experience) để sử dụng cho các tình huống tương lai.
- Cập nhật và cải thiện:
- Thông tin từ các trải nghiệm và phản hồi nội bộ giúp cập nhật và cải thiện hành động của tác nhân trong tương lai.
Khi nào nên sử dụng kỹ thuật phản xạ?
Phản xạ phù hợp nhất cho những điều sau:
- Một tác nhân cần học hỏi từ việc thử và sai: Ký thuật phản xạ được thiết kế để giúp các tác nhân cải thiện hiệu suất của nó bằng cách tìm ra những sai lầm trong quá khứ và kết hợp kiến thức đó vào các quyết định trong tương lai. Điều này làm cho nó phù hợp cho các nhiệm vụ mà tác nhân cần học hỏi thông qua thử và sai, chẳng hạn như ra quyết định, lý luận và lập trình.
- Các phương pháp học tăng cường truyền thống là khó khả thi: Các phương pháp học tăng cường truyền thống (RL) thường yêu cầu dữ liệu đào tạo mở rộng và tinh chỉnh mô hình tốn kém. Reflexion cung cấp một giải pháp thay thế nhẹ nhàng mà không yêu cầu tinh chỉnh mô hình ngôn ngữ cơ bản, giúp mô hình này hiệu quả hơn về mặt dữ liệu và tài nguyên điện toán.
- Cần có phản hồi có sắc thái: Phản hồi sử dụng lời nói, phản hồi này có thể mang nhiều sắc thái và cụ thể hơn so với text được sử dụng trong RL truyền thống. Điều này cho phép tác nhân hiểu rõ hơn các lỗi của mình và thực hiện các cải tiến có mục tiêu hơn trong các thử nghiệm tiếp theo.
- Khi yêu cầu diễn giải và trí nhớ là điều quan trọng: Phản xạ cung cấp một dạng trí nhớ phân đoạn rõ ràng và dễ hiểu hơn so với các phương pháp RL truyền thống. Sự tự phản ánh của tác nhân được lưu trữ trong bộ nhớ của nó, cho phép phân tích và hiểu quá trình học tập của nó dễ dàng hơn.
Phản xạ có hiệu quả trong các nhiệm vụ sau:
- Ra quyết định tuần tự: Các tác nhân phản xạ cải thiện hiệu suất của chúng trong các nhiệm vụ AlfWorld, bao gồm việc điều hướng qua các môi trường khác nhau và hoàn thành các mục tiêu gồm nhiều bước.
- Lý luận: Phản xạ đã cải thiện hiệu suất của các tác nhân trên HotPotQA, một tập dữ liệu trả lời câu hỏi yêu cầu lý luận trên nhiều tài liệu.
- Lập trình: Tác nhân phản xạ viết mã tốt hơn trên các điểm chuẩn như HumanEval và MBPP, đạt được kết quả tiên tiến trong một số trường hợp.
Dưới đây là một số hạn chế của Reflexion:
- Sự phụ thuộc vào khả năng tự đánh giá: Phản ánh dựa vào khả năng của tác nhân để đánh giá chính xác hiệu suất của nó và tạo ra những phản ánh tự hữu ích. Điều này có thể là một thách thức, đặc biệt đối với các nhiệm vụ phức tạp nhưng người ta mong đợi rằng Reflexion sẽ tốt hơn theo thời gian khi các mô hình liên tục cải thiện về khả năng.
- Hạn chế về bộ nhớ dài hạn: Reflexion sử dụng cửa sổ nhớ trượt với dung lượng tối đa nhưng đối với các tác vụ phức tạp hơn, có thể thuận lợi khi sử dụng các cấu trúc nâng cao như vectơ nhúng hoặc cơ sở dữ liệu SQL.
- Hạn chế tạo mã: Có những hạn chế đối với việc phát triển theo hướng thử nghiệm trong việc chỉ định ánh xạ đầu vào-đầu ra chính xác (ví dụ: hàm tạo không xác định và đầu ra hàm bị ảnh hưởng bởi phần cứng).
Kết luận
Reflexion Prompting là một kỹ thuật mạnh mẽ giúp mô hình ngôn ngữ tự đánh giá và cải thiện qua các vòng lặp tự phản hồi. Bằng cách khuyến khích mô hình tự kiểm tra và điều chỉnh câu trả lời của mình, Reflexion giúp nâng cao khả năng suy luận, độ chính xác và tính logic của các phản hồi, mở ra nhiều tiềm năng ứng dụng trong các nhiệm vụ phức tạp và yêu cầu suy luận sâu.