

Chu và cộng sự, (2022) đã đề xuất framework tạo sinh lời nhắc nhở tự động (APE) để tạo và lựa chọn chỉ thị tự động. Các chỉ thị tự động được tạo ra sẽ có dạng ngôn ngữ tự nhiên để giải quyết các vấn đề dưới dạng hộp đen trong LLM nhằm tạo và tìm kiếm các giải pháp phù hợp.
Bước đầu tiên liên quan sẽ sử dụng một mô hình ngôn ngữ lớn (như một mô hình suy luận) nhằm tạo ra một số minh họa hướng dẫn cũng như các biến thể hướng dẫn cho một nhiệm vụ. Những minh hoạ này sẽ hướng dẫn thủ tục tìm kiếm. Các hướng dẫn được thực thi bằng mô hình đích và sau đó hướng dẫn phù hợp nhất được chọn dựa trên điểm đánh giá được tính toán.
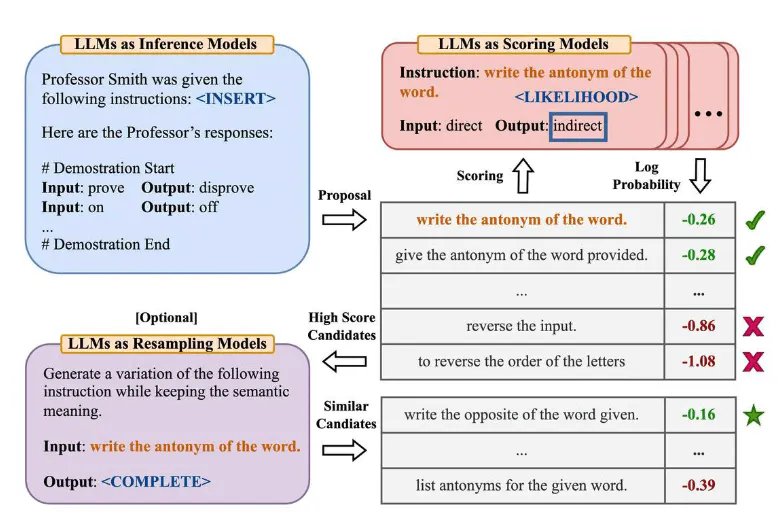
Giải thích về lược đồ:
1. LLMs as Inference Models
- Mô hình Suy luận (Inference Models):
- Đầu vào (Input): Một lệnh hoặc yêu cầu cụ thể, ví dụ: “prove”.
- Đầu ra (Output): Phản hồi của mô hình đối với lệnh, ví dụ: “disprove”.
- Trong phần này, chúng ta giả định rằng Giáo sư Smith nhận được các hướng dẫn và đã cung cấp các phản hồi tương ứng trong <INSERT>.
2. LLMs as Scoring Models
- Mô hình Chấm điểm (Scoring Models):
- Đề xuất (Proposal): Một biến thể của lời nhắc ban đầu cần được đánh giá.
- Chấm điểm (Scoring): Đánh giá khả năng hoặc xác suất của các biến thể này dựa trên sự phù hợp và xác suất log (log probability).
- Ví dụ: Với hướng dẫn “write the antonym of the word” (viết từ trái nghĩa của từ đó), các biến thể như “give the antonym of the word provided” (cung cấp từ trái nghĩa của từ được đưa ra) hoặc “reverse the input” (đảo ngược đầu vào) sẽ được chấm điểm.
3. LLMs as Resampling Models (Optional)
- Mô hình Tái lấy mẫu (Resampling Models):
- Đầu vào (Input): Lời nhắc ban đầu, ví dụ: “write the antonym of the word”.
- Đầu ra (Output): Một biến thể của lời nhắc mà vẫn giữ nguyên ý nghĩa, ví dụ: “write the opposite of the word given”.
- Mục đích: Tạo ra các biến thể khác nhau của lời nhắc ban đầu để tối ưu hóa khả năng đáp ứng của mô hình.
Quy trình Hoạt động
- Đề xuất (Proposal):
- Lời nhắc ban đầu được đưa ra, ví dụ: “write the antonym of the word”.
- Chấm điểm và Xác suất Log (Scoring and Log Probability):
- Các biến thể của lời nhắc được chấm điểm dựa trên khả năng xuất hiện và độ phù hợp.
- Những biến thể có điểm số cao hơn (log probability thấp hơn) được coi là phù hợp hơn.
- Ví dụ: “write the antonym of the word” (-0.26) được đánh giá cao hơn so với “reverse the input” (-0.86).
- Lựa chọn Kết quả (High Score Candidates):
- Các biến thể có điểm số cao sẽ được chấp nhận và sử dụng.
- Kết quả Tương tự (Similar Candidates):
- Các biến thể có ý nghĩa tương tự cũng có thể được xem xét và so sánh, ví dụ: “write the opposite of the word given” (-0.16).
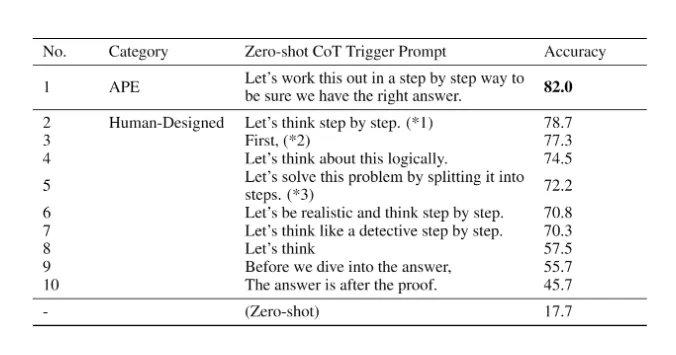
APE phát hiện ra lời nhắc CoT zẻo-shot tốt hơn lời nhắc “Hãy suy nghĩ từng bước – CoT” do con người tạo ra (Kojima và cộng sự, 2022).
Lời nhắc “Hãy giải quyết vấn đề này từng bước một để đảm bảo chúng ta có câu trả lời đúng.” khơi gợi lý luận theo chuỗi suy nghĩ và cải thiện hiệu suất trên các điểm chuẩn MultiArith và GSM8K:
Bài viết này đề cập đến một chủ đề quan trọng liên quan đến kỹ thuật nhắc nhở, đó là ý tưởng tự động tối ưu hóa các lời nhắc thông qua các mô hình ngôn ngữ. Mặc dù chúng ta không đi sâu vào chủ đề này trong hướng dẫn này nhưng đây là một số bài báo khoa học nếu bạn quan tâm tìm hiểu sâu hơn:
- Nhắc-OIRL – đề xuất sử dụng phương pháp học tăng cường nghịch đảo ngoại tuyến để tạo ra các lời nhắc phụ thuộc vào truy vấn.
- OPRO – giới thiệu ý tưởng sử dụng LLM để tối ưu hóa lời nhắc: để LLM “Hít một hơi thật sâu” nâng cao hiệu quả giải các bài toán.
- AutoPrompt – đề xuất một phương pháp tự động tạo lời nhắc cho một nhóm nhiệm vụ đa dạng dựa trên tìm kiếm theo hướng dẫn độ dốc.
- Prefix Tuning – một giải pháp thay thế nhẹ nhàng cho việc tinh chỉnh bổ sung tiền tố liên tục có thể huấn luyện cho các nhiệm vụ NLG.
- Prompt Tuning – đề xuất một cơ chế học các nhắc nhở mềm thông qua lan truyền ngược.