


Tương lai là thông minh
Trí tuệ nhân tạo (AI) là một lĩnh vực của khoa học máy tính chuyên sâu vào việc phát triển các hệ thống có trí tuệ giống như con người. Năm 1950, nhà toán học và nhà khoa học máy tính người Anh Alan Turing đã sáng tạo Ra Kiểm tra Turing: một cách để xác định xem một máy có khả năng thể hiện trí tuệ tương đương với con người hay không. Kể từ đó, trí tuệ nhân tạo đã phát triển mạnh mẽ.
Trí tuệ nhân tạo: một lược sử ngắn

Vào những năm 1950, các nhà nghiên cứu bắt đầu phát triển máy tính có khả năng suy nghĩ logic và giải quyết vấn đề. Chatbot đầu tiên giao tiếp với con người vào năm 1966, trí tuệ nhân tạo bước vào lĩnh vực y học vào đầu những năm 1970, và vào năm 1997, máy cờ vua AI Deep Blue đã đánh bại nhà vô địch cờ vua thế giới đương nhiệm, Garry Kasparov, trong một giải đấu. Tiến triển đáng kể đã được đạt được trong lĩnh vực học máy và mạng nơ-ron, và các hệ thống trí tuệ nhân tạo đã bắt đầu làm việc với lượng dữ liệu lớn hơn và sức mạnh tính toán lớn hơn. Kết quả là, trí tuệ nhân tạo đã trở nên mạnh mẽ hơn theo thời gian. Ngày nay, chúng ta thấy trí tuệ nhân tạo được ứng dụng rộng rãi trong các lĩnh vực như nhận dạng giọng nói và hình ảnh, phương tiện tự động và hệ thống đề xuất cá nhân.
Trí tuệ nhân tạo dành cho đại số đông
ChatGPT là một chatbot có thể tham gia vào cuộc trò chuyện giống như con người. Nó hiểu ngôn ngữ tự nhiên và tạo ra các câu trả lời ngữ cảnh cho các câu hỏi và tuyên bố. Với sự hỗ trợ của học máy và việc đào tạo trên một bộ dữ liệu phong phú, ChatGPT có thể trả lời các câu hỏi, viết văn bản sáng tạo hoặc tạo ra mã. Nói một cách ngắn gọn, nó có thể hỗ trợ trong nhiều cách khác nhau. Các đại gia trong ngành cũng đã làm theo với những mô hình tương tự: Google đã phát hành PaLM 2 thông qua API vào cuối tháng 5 năm 2023, và đã có các mô hình mã nguồn mở như Falcon 180B, thực hiện ở mức độ tương tự như GPT-3.5.
Cách chatbot thông minh thu thập kiến thức của mình

Các mô hình ngôn ngữ như mô hình GPT-4 đằng sau ChatGPT đều thuộc vào thuật ngữ “mô hình ngôn ngữ lớn” – hay LLMs tắt gọn. Những mô hình mạnh mẽ này, có khả năng xử lý hình ảnh, video và tệp âm thanh ngoài văn bản, được đào tạo trên các bộ dữ liệu lớn bằng cách sử dụng học máy. Điều này mang lại cho chúng một phạm vi kiến thức rộng lớn, bao gồm nhiều lĩnh vực khác nhau.
Không chỉ là “Google với những ưu điểm”?
Nhiều người xem xét chatbot dựa trên trí tuệ nhân tạo như ChatGPT như một phiên bản thông minh hơn của Google, sử dụng nó như một công cụ tìm kiếm toàn cầu và để trả lời các câu hỏi. Nhưng những công cụ này có thể mang lại nhiều hơn chỉ là câu trả lời chính xác và thu hút ngôn ngữ cho các câu hỏi phức tạp. Ví dụ, chúng có thể ngay lập tức tạo ra một bản trình bày PowerPoint được tinh chỉnh cho một nhóm đối tượng cụ thể từ câu trả lời cho một câu hỏi phức tạp. Điều này cho thấy tại sao chatbot AI dựa trên LLM là một bước đổi trò chơi: Trước đây, các giải pháp công nghệ phải được lập trình cho các trường hợp sử dụng cụ thể. Nhưng bây giờ, những mô hình thông minh mới này có thể thực hiện nhiều nhiệm vụ khác nhau và do đó có thể được sử dụng trong các trường hợp sử dụng khác nhau. ChatGPT và các đồng đội của nó là những công cụ đa năng có thể thực hiện các nhiệm vụ mà chúng chưa được phát triển đặc biệt cho.
Áp dụng các LLM hiện tại trong các trường hợp sử dụng cụ thể của tổ chức

Việc phát triển các LLM như GPT-4 không chỉ là thú vị đối với người dùng. Trong quá khứ, các dự án học máy và trí tuệ nhân tạo thường đầy thách thức và đòi hỏi nhiều công sức. Nhưng bây giờ, LLMs đang mở ra một cách tiếp cận hoàn toàn mới. Chuyên gia trí tuệ nhân tạo có thể sử dụng các LLM hiện tại để tạo ra các giải pháp trí tuệ nhân tạo cho các công ty trong mọi ngành. Điều này làm cho quá trình trở nên mạch lạc, giúp giảm chi phí so với trước đây. Thay vì thu thập dữ liệu và đào tạo mô hình trong nội bộ, hiện nay thường chỉ cần tích hợp dữ liệu của công ty là đủ để bắt đầu. Có thể sử dụng phương pháp tăng cường thông tin truy xuất, hay RAG, ở đây. Tiếp theo, đó là việc đặt câu hỏi đúng với sự hỗ trợ của kỹ thuật đặt câu hỏi, trong những gì được biết đến là học không giáo viên, hay zero-shot learning.
Kỹ thuật đặt câu hỏi: Ngôn ngữ tự nhiên như một ngôn ngữ lập trình mới
Người dùng tương tác với các giải pháp như ChatGPT bằng cách sử dụng các câu hỏi. Dựa trên những câu hỏi này, mô hình tạo ra toàn bộ kết quả từng từ một. “Giải thích trong hai câu không có dấu phẩy và dễ hiểu cho học sinh tiểu học cách tạo ra cầu vồng” là một ví dụ về một câu hỏi. Một câu hỏi mô tả đầu vào cho mô hình, tương tự như một lệnh. Nói một cách đơn giản, bạn có thể coi một câu hỏi như là mã được viết bằng ngôn ngữ tự nhiên: Trong khi một chương trình máy tính phải giải thích mã một cách đúng để thực hiện hành động mà lập trình viên muốn, một giải pháp trí tuệ nhân tạo sáng tạo như ChatGPT phải giải thích một câu hỏi đúng để tạo ra câu trả lời mong muốn. Các câu hỏi tốt phải được chính xác và giới hạn các câu trả lời có thể để đạt được kết quả tốt. Đó là lý do tại sao việc viết câu hỏi cần phải xem xét những đặc điểm cụ thể của mô hình.
Dữ liệu và bối cảnh: Thông tin mà các LLM như GPT-4 sử dụng là gì?

Các mô hình ngôn ngữ trí tuệ nhân tạo đã được đào tạo trên một tập dữ liệu lớn. Thông thường, đây bao gồm một số lượng lớn các nguồn trực tuyến từ Internet, chẳng hạn như các trang web thông tin (ví dụ: Wikipedia), sách, bài báo tin tức, công bố khoa học và bài đăng trên blog. GPT-4, được đào tạo trên dữ liệu đến tháng 9 năm 2021 và được bổ sung thêm dữ liệu đến tháng 4 năm 2023 trong phiên bản GPT-4 Turbo mới nhất, cũng sử dụng các nguồn dữ liệu độc quyền với chất lượng dữ liệu cao. Bằng cách sử dụng các plug-in, các LLMs được sản xuất bởi OpenAI và Google cũng có thể truy cập các kết quả tìm kiếm hiện tại.
Ngoài tập dữ liệu đào tạo, LLMs cũng có thể được cung cấp với dữ liệu cụ thể của công ty mà mô hình chưa được đào tạo. Điều này được biết đến là việc cung cấp ngữ cảnh. Dữ liệu cụ thể của tổ chức này có thể đến từ trang web của công ty, SharePoint hoặc các nguồn dữ liệu khác, và có thể ở định dạng văn bản, hình ảnh hoặc video. Số lượng dữ liệu có thể thêm vào bị giới hạn và thay đổi tùy thuộc vào mô hình. GPT-4 có thể xử lý khoảng 50 trang văn bản như các bối cảnh được thêm vào câu hỏi, hoặc lên đến 300 trang trong phiên bản GPT-4 Turbo mới nhất của nó. Một câu hỏi có thể là: “Tóm tắt bài báo trắng này thành mười câu cho một trang đích, chú ý đến từ khóa tốt.” Bài báo trắng phải được bao gồm làm ngữ cảnh cho câu hỏi.
Vì chỉ có thể cung cấp một lượng ngữ cảnh hạn chế, không thể bao gồm toàn bộ dữ liệu cụ thể của công ty trong câu hỏi. Vấn đề này có thể được giải quyết bằng cách sử dụng embeddings. Embeddings là các vector biểu diễn ý nghĩa của một phần cụ thể của văn bản. Các tài liệu nội bộ của công ty được chuyển đổi thành embeddings và lưu trữ trong một cơ sở dữ liệu vector. Câu hỏi của người dùng cũng được chuyển đổi thành một embedding, và chatbot tìm kiếm trong cơ sở dữ liệu để tìm các tài liệu liên quan cho embedding đó. Các tài liệu liên quan và câu hỏi được cung cấp cho LLM như ngữ cảnh. LLM sau đó sử dụng điều này để trả lời câu hỏi.
Một ví dụ khác về ngữ cảnh là các yêu cầu chỉ có thể được trả lời với dữ liệu web được cập nhật hàng ngày. Vì dữ liệu được sử dụng để đào tạo các mô hình tĩnh dừng lại tại một thời điểm nhất định, một cuộc tìm kiếm web được thực hiện và thông tin được cung cấp cho mô hình như ngữ cảnh. Ví dụ: Một nhân viên cần đi du lịch đến London và nhập câu hỏi sau đây vào chatbot: “Tôi muốn đặt vé máy bay đến London và một khách sạn ở đó. Khách sạn phải gần sân bay. Kỳ nghỉ: từ ngày 1 đến ngày 5 tháng 12 năm 2023.” Khi người dùng nhập câu hỏi, chatbot thực hiện một truy vấn tìm kiếm và chèn kết quả về giá khách sạn, thời gian chuyến bay, và những thứ khác vào câu hỏi. Ngoài ra, hướng dẫn du lịch của công ty cũng được thêm vào câu hỏi. Dựa trên ngữ cảnh này, chatbot sau đó đề xuất một chuyến đi mà nhân viên có thể điều chỉnh bằng các câu hỏi mới như “Tôi có thể ở một khách sạn sang trọng hơn một chút không?” cho đến khi họ hài lòng với chuyến đi.
Tinh chỉnh (fine-tuning) theo nhu cầu của bạn

Các công ty có lượng lớn dữ liệu sẵn có: dữ liệu từ giao tiếp của khách hàng như cuộc gọi điện thoại, trò chuyện và email, cũng như dữ liệu nội bộ từ các tài liệu lưu trữ trên hệ thống mạng nội bộ và máy chủ hoặc trong các cơ sở dữ liệu khác. Với một trợ lý trí tuệ nhân tạo được tùy chỉnh, dữ liệu cụ thể của công ty này có thể được kết hợp với sức mạnh và trí tuệ của ChatGPT để phát triển một giải pháp chatbot thông minh cho nhân viên và khách hàng. Trợ lý trí tuệ nhân tạo có thể giúp nhân viên sử dụng dữ liệu hiện tại một cách hiệu quả và mục đích hơn, tự động hóa các quy trình, củng cố mối quan hệ với khách hàng, hoặc phát triển sản phẩm và dịch vụ mới. Ngược lại, khách hàng nhận được một bot thông minh có thể đáp ứng các yêu cầu của họ. Điều này hoàn toàn có thể được thực hiện trong khi tuân theo các quy định về bảo vệ dữ liệu đang áp dụng trong lãnh thổ của công ty.
Phân tích giao tiếp của khách hàng với LLMs

Hầu hết mọi công ty bán lẻ lớn đều thu thập lượng lớn dữ liệu thông qua giao tiếp của khách hàng như cuộc gọi điện thoại, email và trò chuyện. Dữ liệu này có thể được phân tích để trả lời các câu hỏi như “Khách hàng có hài lòng với sản phẩm của chúng tôi không?”, “Nếu không: tại sao?” và các câu hỏi tương tự một cách tương đối dễ dàng. Bước đầu tiên là chuyển đổi các cuộc gọi điện thoại đã ghi âm thành văn bản. Có các mô hình trí tuệ nhân tạo có khả năng chuyển đổi lời nói – bao gồm các thổ ngữ – thành văn bản cho mục đích này. Khi giao tiếp bằng lời nói được biểu đạt dưới dạng văn bản, nó có thể được ẩn danh để loại bỏ mọi tham chiếu đến dữ liệu cá nhân và được phân tích với GPT-4. Tuy nhiên, các câu hỏi đúng phải được phát triển tùy thuộc vào từng trường hợp sử dụng. Khi đến việc tóm tắt một cuộc trò chuyện một cách đơn giản, một câu hỏi đơn giản như “Vui lòng tóm tắt cuộc trò chuyện sau đây trong ba câu ngắn gọn, súc tích.” là đủ. Các câu hỏi trở nên hơi dài hơn đối với các trường hợp sử dụng khác. Ví dụ, các tương tác đã ghi âm có thể được tìm kiếm thông tin cụ thể để khởi động chiến dịch dành riêng cho sản phẩm và khách hàng.
Trợ lý ảo trí tuệ nhân tạo với dữ liệu của công ty

Nhưng nếu một công ty có thể cung cấp cho khách hàng của mình một trợ lý trí tuệ nhân tạo thực sự thông minh có thể cung cấp câu trả lời chính xác về sản phẩm và dịch vụ của mình? Một trợ lý trí tuệ nhân tạo có quyền truy cập thông tin cụ thể cho từng khách hàng và có thể sử dụng nó để trả lời các câu hỏi phức tạp như, “Tôi đã chi bao nhiêu tiền cho sản phẩm X và Y năm ngoái?” Điều này có thể thực hiện bằng cách kết hợp LLM thông minh, như GPT-4, với dữ liệu của công ty (từ hệ thống mạng nội bộ, máy chủ, v.v.).
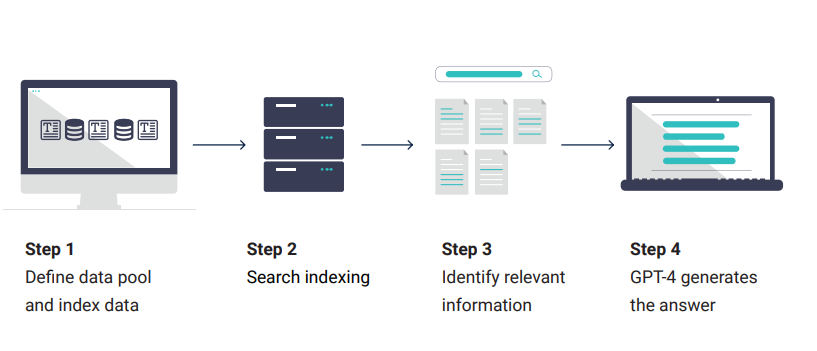
Bước đầu tiên là lập chỉ mục tất cả dữ liệu liên quan của công ty. Dữ liệu đã được lập chỉ mục sau đó được lưu trữ trong một chỉ mục tìm kiếm, thường ở dạng embeddings. Giả sử một người dùng bây giờ đặt một câu hỏi cụ thể như “Dịch vụ XY đã tốn bao nhiêu tiền trong năm XZ?” Trong trường hợp này, bước đầu tiên là sử dụng các mô hình truy xuất để tìm kiếm trong các tài liệu có thể chứa câu trả lời cho câu hỏi. Có thể có năm tài liệu hoặc nhiều đến 50. Quan trọng là một số lượng lớn các tài liệu không liên quan có thể được loại trừ rất nhanh chóng. Những tài liệu còn lại được gửi đến GPT-4 cùng với câu hỏi và mọi thông tin khác. GPT-4 đọc các tài liệu được gửi, kết hợp các sự kiện liên quan và viết một câu trả lời logic liên quan đến các tài liệu nguồn. Trợ lý trí tuệ nhân tạo sau đó trình bày câu trả lời và nguồn cho người dùng. Tổ chức có thể chọn phương tiện – một chatbot trên trang web, tích hợp trong MS Teams hoặc WhatsApp, hoặc thậm chí là một câu trả lời tự động qua email – tùy thuộc vào sở thích của họ.
Từ đào tạo đến tích hợp
Hành trình áp dụng trí tuệ nhân tạo sẽ là duy nhất đối với mỗi công ty. Là đối tác, chúng tôi sẽ hỗ trợ bạn ở mọi giai đoạn trong quá trình này với Chặng Đường Trí Tuệ Nhân Tạo của chúng tôi và giúp bạn tận dụng toàn bộ tiềm năng của trí tuệ nhân tạo. Chúng tôi tiếp cận theo cách tích hợp:
Bạn quyết định nơi sử dụng và mức độ hỗ trợ bạn cần từ chúng tôi. Hãy cùng nhau giải quyết dự án Trí Tuệ Nhân Tạo tiếp theo của bạn!
—-

Ursin Brunner là một kỹ sư phần mềm sở hữu bằng thạc sĩ về học máy. Trí tuệ nhân tạo là một trong những đam mê lớn nhất của anh ấy. Khi AlphaGo đánh bại cầu thủ Go hàng đầu thế giới vào năm 2016, Ursin quyết định rằng AI không chỉ là sự hứng thú thoáng qua. Đam mê của anh ấy đã trở thành nghề nghiệp, và hiện tại anh ấy là người đứng đầu nhóm AI/ML tại ti&m cùng với Pascal Wyss.