


Tác giả: Jesus Rodriguez
Hướng tới Trí Tuệ Nhân Tạo
Cảnh quan của cảnh tranh trí tuệ nhân tạo sinh sôi động mạnh mẽ trong cộng đồng mã nguồn mở đang trở nên vô cùng sôi động. Sự đổi mới không chỉ đến từ các startup như HuggingFace, Mistral, hoặc AI21 mà còn từ các phòng thí nghiệm trí tuệ nhân tạo lớn như Meta. Databricks đã là một trong những công ty công nghệ đi đầu khám phá các góc nhìn khác nhau trong trí tuệ nhân tạo mã nguồn mở, chủ yếu sau khi mua lại MosaicML. Vài ngày trước, Databricks đã công bố mã nguồn mở DBRX, một mô hình LLM (Large Language Model) tổng quát khổng lồ mà cho thấy hiệu suất không tưởng trên các tiêu chuẩn khác nhau.
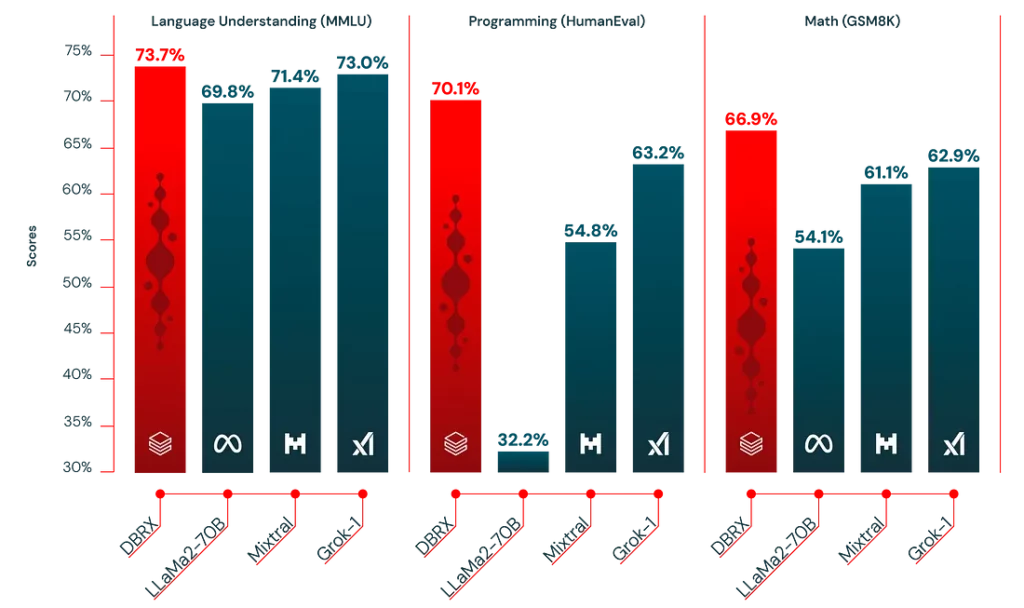
DBRX được xây dựng dựa trên phương pháp kết hợp của các chuyên gia (MoE) được sử dụng bởi Mixtral, dường như đang trở nên ngày càng là tiêu chuẩn để theo đuổi trong các cấu trúc dựa trên bộ biến đổi. Databricks đã phát hành cả hai mô hình cơ bản DBRX Base cũng như mô hình được điều chỉnh fine-tuned DBRX Instruct. Từ các báo cáo ban đầu, dường như lợi thế của Databricks là chất lượng của tập dữ liệu và quy trình huấn luyện, tuy nhiên, có rất ít chi tiết về điều đó.
Kiến trúc
DRRX là một mô hình ngôn ngữ lớn hoạt động trên một cấu trúc dựa trên bộ biến đổi, chỉ có bộ giải mã, được thiết kế đặc biệt để dự đoán token tiếp theo trong một chuỗi. Nó được xây dựng dựa trên một cấu trúc phức tạp của hỗn hợp các chuyên gia (MoE) có tổng cộng 132 tỷ tham số, mặc dù chỉ sử dụng 36 tỷ tham số cho bất kỳ đầu vào cụ thể nào. Mô hình này được làm giàu thông qua việc huấn luyện trên một tập dữ liệu gồm 12 nghìn tỷ token, bao gồm cả văn bản và mã nguồn. DBRX tạo ra sự khác biệt bằng cách sử dụng một phương pháp tinh tế hơn với 16 chuyên gia nhỏ hơn, trong đó có 4 được chọn cho một nhiệm vụ, không giống như các đối thủ cùng thời, Mixtral và Grok-1, sử dụng 8 chuyên gia và chọn 2. Phương pháp này dẫn đến một số lượng kết hợp chuyên gia tiềm năng tăng lên đáng kể — chính xác là 65 lần nhiều hơn — cải thiện chất lượng của mô hình. Base tích hợp các kỹ thuật tiên tiến như mã hóa vị trí xoay, đơn vị tuyến tính có cổng, và sự chú ý câu hỏi được nhóm để cải thiện hiệu suất, và nó sử dụng bộ mã hóa token GPT-4.
Tập dữ liệu cho việc huấn luyện của DBRX đã được tỉ mỉ tổ chức và tin rằng hiệu quả gấp đôi, token cho token, so với dữ liệu được sử dụng trong các mô hình trước đó do tổ chức phát triển. Tập dữ liệu mới này được hưởng lợi từ các công cụ xử lý và quản lý dữ liệu toàn diện, giúp tối ưu hóa chế độ huấn luyện được đặc biệt cải thiện chất lượng mô hình thông qua các điều chỉnh chiến lược trong hỗn hợp dữ liệu.
Huấn luyện
Quá trình phát triển của DBRX kéo dài trong ba tháng, dựa vào 3072 GPU NVIDIA H100 được kết nối qua mạng Infiniband với băng thông 3.2Tbps. Thời kỳ này đánh dấu sự kết thúc của công việc chuẩn bị một cách tỉ mỉ, bao gồm nghiên cứu tập dữ liệu và các thí nghiệm về tỷ lệ, tất cả đều là phần của sự tiến triển liên tục trong việc phát triển mô hình ngôn ngữ. Đáng chú ý, việc huấn luyện biến thể MoE của Base đã chứng minh được hiệu suất tính toán đáng kể hơn so với các mô hình truyền thống.
Sự tiến bộ hiệu quả này là một phần của sự tiến bộ toàn diện trong quy trình huấn luyện của mô hình, hiện giờ gần bốn lần hiệu quả tính toán hơn so với mười tháng trước. Những cải tiến hiệu quả như vậy đã được đạt được thông qua sự kết hợp của các đổi mới kiến trúc, các kỹ thuật tối ưu hóa, và, quan trọng nhất, việc sử dụng dữ liệu huấn luyện chất lượng cao hơn.
Trong suốt quá trình phát triển của DBRX, một bộ công cụ độc quyền đã được sử dụng cho quản lý dữ liệu, xử lý và huấn luyện mô hình, đảm bảo một luồng làm việc mượt mà và tích hợp. Các công cụ này cho phép khám phá một cách tỉ mỉ, làm sạch dữ liệu và huấn luyện mô hình hiệu quả trên một loạt lớn các GPU, dẫn đến một quy trình tinh giản cho việc tinh chỉnh và triển khai mô hình.
Suy luận
Kiến trúc của DBRX cho phép một sự cân bằng tinh tế giữa chất lượng mô hình và hiệu suất suy luận, vượt trội so với các mô hình dày đặc trong lĩnh vực này. Ví dụ, mặc dù có kích thước lớn, DBRX đạt được gấp đôi lưu lượng suy luận so với các mô hình tương tự nhờ vào việc sử dụng hiệu quả các tham số hoạt động. Mô hình cung cấp các chỉ số hiệu suất nâng cao trên nhiều tiêu chuẩn, đặt ra các tiêu chuẩn mới cho cả chất lượng và hiệu suất.
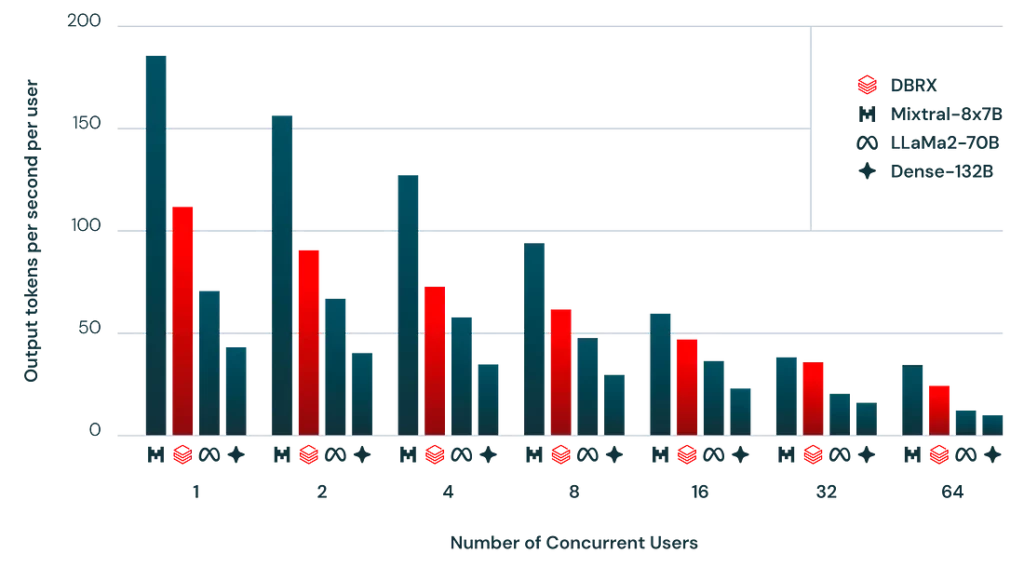
DBRX Instruct
DBRX cũng có một phiên bản chuyên biệt được thiết kế cho các nhiệm vụ theo dõi hướng dẫn, được biết đến với tên gọi DBRX Instruct. Biến thể này chia sẻ kiến trúc MoE, sử dụng một phương pháp huấn luyện đích đến để xuất sắc trong các ứng dụng yêu cầu tương tác ngắn gọn.
Đánh giá
DBRX và biến thể theo dõi hướng dẫn của nó đã được đánh giá một cách nghiêm ngặt so với cả các mô hình mã nguồn mở và thương mại, thể hiện hiệu suất vượt trội qua một loạt các chỉ số, bao gồm kiến thức tổng quát, suy luận phổ thông, và các lĩnh vực chuyên biệt như lập trình và toán học.
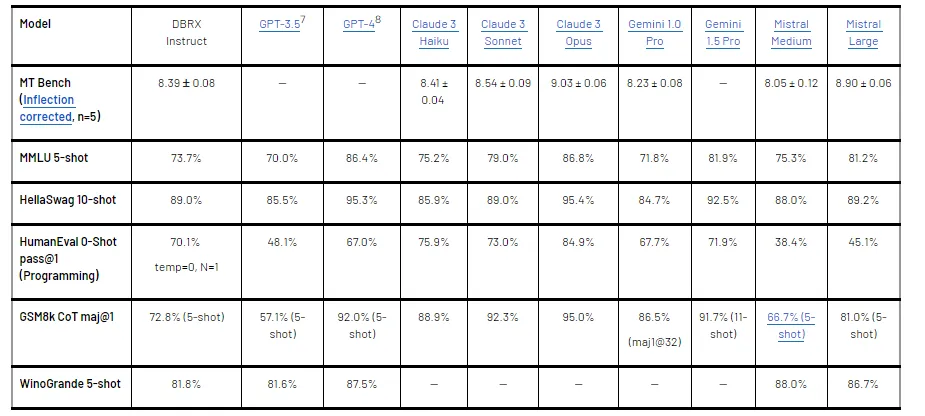
Mô hình thể hiện sự thành thạo đáng kinh ngạc trong việc xử lý các yêu cầu có ngữ cảnh dài, cung cấp cái nhìn sâu sắc vào khả năng của nó và các ứng dụng tiềm năng trong các lĩnh vực khác nhau.
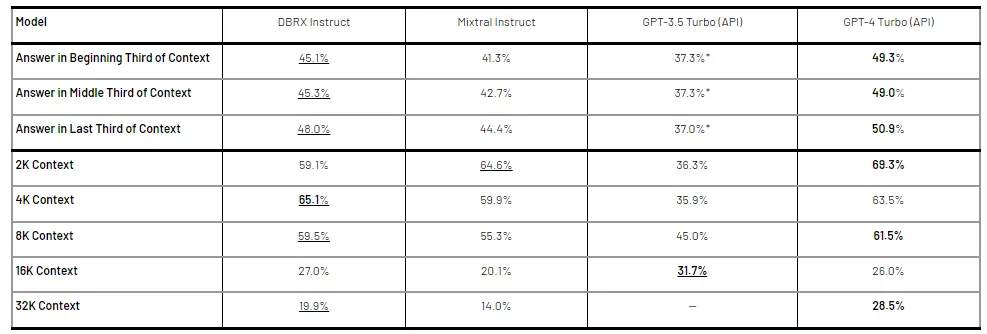
RAG là một lĩnh vực khác mà DBRX làm rất xuất sắc.

Sử dụng DBRX
DBRX và DBRX Instruct có sẵn để triển khai thông qua nền tảng HuggingFace, đảm bảo một quy trình tích hợp dễ dàng cho người dùng. Các mô hình yêu cầu bộ nhớ đáng kể cho hoạt động nhưng hứa hẹn là một bộ công cụ mạnh mẽ để giải quyết các nhiệm vụ phức tạp về hiểu và tạo ra ngôn ngữ, như được thể hiện qua các ví dụ thực tế.
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
tokenizer = AutoTokenizer.from_pretrained("databricks/dbrx-instruct", trust_remote_code=True, token="hf_YOUR_TOKEN")
model = AutoModelForCausalLM.from_pretrained("databricks/dbrx-instruct", device_map="cpu", torch_dtype=torch.bfloat16, trust_remote_code=True, token="hf_YOUR_TOKEN")
input_text = "What does it take to build a great LLM?"
messages = [{"role": "user", "content": input_text}]
input_ids = tokenizer.apply_chat_template(messages, return_dict=True, tokenize=True, add_generation_prompt=True, return_tensors="pt")
outputs = model.generate(**input_ids, max_new_tokens=200)
print(tokenizer.decode(outputs[0]))DBRX đại diện cho một bước nâng cấp lớn LLM của Databricks. Cùng với bản trả phí dành cho doanh nghiệp, DBRX có thể trở thành một trong những mô hình LLM mã nguồn mở quan trọng nhất trong làn sóng trí tuệ nhân tạo tạo sinh năm 2024.