


Ngày 10/8/2023 mô hình ngôn ngữ lớn có tên Vietcuna đã được một nhóm các kỹ sư AI Việt Nam giới thiệu nhắm tới xử lý tiếng Việt dành riêng cho thị trường Việt Nam với dữ liệu đào tạo hoàn toàn bằng tiếng Việt đã đến tay cộng đồng dưới dạng mã nguồn mở. Đây là một nỗ lực đáng ghi nhận trong điều kiện nguồn lực hạn chế và được đóng góp bởi các cá nhân tình nguyện tham gia dự án.
Thông tin về dự án bạn có thể tìm hiểu:
- Website dự án: https://www.vilm.org/
- Mô hình 3 tỉ tham số: Truy cập
- Mô hình 7 tỉ tham số: Truy cập
- Mô hình 40 tỉ tham số: Truy cập (cập nhật ngày 2/10/2023 hỗ trợ 12 ngôn ngữ)
- Mô hình 180 tỉ tham số: Truy cập (cập nhật ngày 2/10/2023 hỗ trợ 12 ngôn ngữ)
Vietcuna dựa xây dựng dựa trên trên BLOOMZ LLM của BigScience bước đầu được huấn luyện dựa vào 12GB dữ liệu công khai được quét từ các báo chí công cộng tại Việt Nam như VnExpress, Zing News, BaoMoi,… đồng thời được tinh chỉnh với trên 200.000 bộ câu hỏi hướng dẫn và hơn 400.000 đoạn hội thoại tiếng Việt. Vietcuna hiện thời cung cấp giao tiếp với độ dài bối cảnh 2048 ký tự.
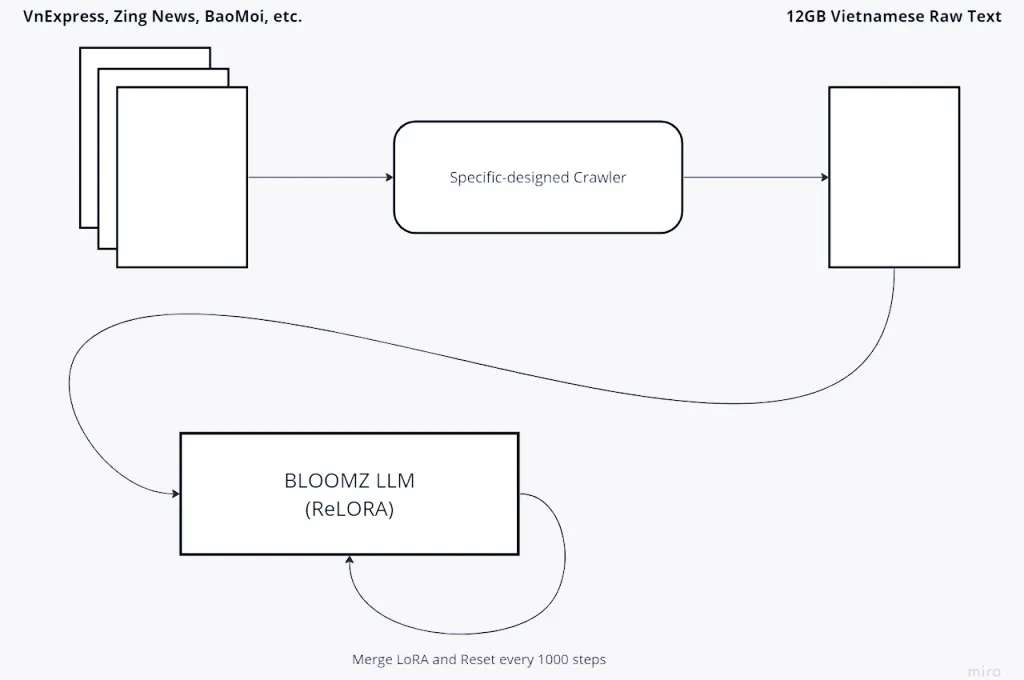
Theo thông tin từ nhóm thực hiện dự án, sau khi cân nhắc và đánh giá một số mô hình ngôn ngữ nền tảng được phát hành dưới dạng nguồn mở để có thể dựa vào phát triển như LLaMA, GPT-J, GPT-2 và BLOOM/BOOMZ, nhóm đã lựa chọn BLOOM/BOOMZ xuất phát từ nguyên nhân mô hình này đã được huấn luyện trước với dữ liệu giảng dạy đáp ứng nhiều tác vụ đồng thời nó cung cấp nhiều hơn các biến thể nhỏ (3 tỉ và 7 tỉ tham số) cho phép có thể thực hiện được trên những nền tảng phần cứng xử lý hạn chế.
Tinh chỉnh cho giảng dạy và hội thoại
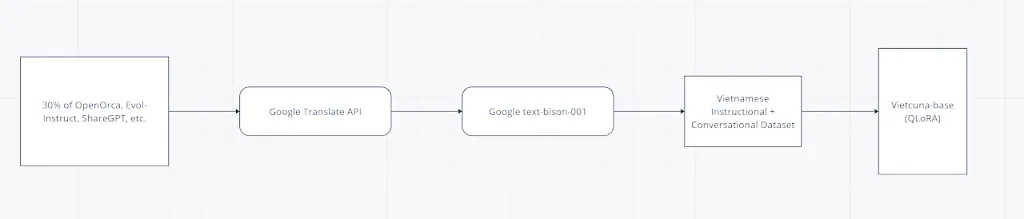
Theo tài liệu công bố về cách thức huấn luyện của nhóm dự án, nhóm đã sử dụng các kỹ thuật tăng cường dữ liệu phổ biến bao gồm Evol-Instruct, ShareGPT, Orca, Chain-of-Thought và Alpaca. Nhóm thực hiện đã dịch 30% số tập dữ liệu đó sang tiếng Việt thông qua API Google Translate và sau đó sử dụng text-bison-001 của Google để bổ sung thêm dữ liệu tổng hợp. Bộ dữ liệu được tinh chỉnh hoàn chỉnh bao gồm 200 nghìn mẫu câu hỏi và câu trả lời hướng dẫn cùng với 400 nghìn mẫu hội thoại.
Cuối cùng, nhóm chọn QLoRA (Dettmers et al, 2023) làm phương pháp tinh chỉnh vì nó có thể áp dụng để tinh chỉnh với phần cứng có nguồn tài nguyên thấp. Tuy nhiên, nhóm đã áp dụng QLoRA cho tất cả các lớp tuyến tính để giúp LLM thích ứng với các tác vụ phức tạp hơn thay vì chỉ các lớp chú ý.
Chi tiết kỹ thuật và khả năng tiếp cận
Cả hai mô hình đều được cung cấp miễn phí theo giấy phép APACHE-2.0, đảm bảo rằng chúng có thể được tích hợp vào nhiều ứng dụng một cách dễ dàng. Tuy nhiên, điều quan trọng cần lưu ý là Falcon-180B, mẫu cơ bản, hoạt động theo giấy phép cụ thể và chính sách sử dụng được chấp nhận.
Đối với những người quan tâm đến thông số kỹ thuật phần cứng, Vulture-180B yêu cầu khoảng 8xA100 80GB hoặc tương đương để có độ chính xác đầy đủ của bfloat16. Mặt khác, Vulture-40B được thiết kế để chạy hiệu quả trên các thiết lập ít tiêu tốn tài nguyên hơn, khiến nó phù hợp với các dự án quy mô nhỏ hơn.
Sự chấp nhận của cộng đồng
Theo thông tin được công bố trên website, Vietcuna đã đạt được những con số đáng kinh ngạc với hơn 36.000 người dùng trên Web Playground của dự án và hơn 12.000 lượt tải xuống trên HuggingFace.
Với sự ra đời của Vietcuna dưới dạng nguồn mở, nhóm thực hiện mong muốn sẽ mở ra một kỷ nguyên mới về tiến bộ công nghệ của Việt Nam đồng thời đạt được những bước tiến trong việc thu hẹp khoảng cách về đại diện AI.
Không chỉ là một mô hình ngôn ngữ đơn thuần, Vietcuna còn là một công cụ mạnh mẽ hỗ trợ các doanh nghiệp Việt Nam định hướng những lĩnh vực đổi mới chưa được khám phá.
Bằng cách tinh chỉnh mô hình này để phù hợp với các sắc thái ngôn ngữ và văn hóa độc đáo của dự án, nhóm thực hiện mong muốn Vietcuna sẽ là động lực tạo ra các giải pháp công nghệ phù hợp với cộng đồng địa phương và mở rộng ra ngoài biên giới.
Hơn nữa, với nguồn mở của Vietcuna và hệ thống dữ liệu của nó, nhóm mong muốn thiết lập một kế hoạch chi tiết cho các ngôn ngữ khác, thúc đẩy con đường phát triển LLM riêng nhanh hơn và hiệu quả hơn đồng thời giảm thiểu khoảng cách tiếp cận AI và định hình lại câu chuyện công nghệ toàn cầu cho từng ngôn ngữ.